Otros
SDG
Para consultar los datos del Índice de los ODS con R, descargaremos los datos y los situaremos en el directorio de trabajo, tal como hemos visto anteriormente en la Guía de RStudio. Deberemos tener cargados los paquetes readxl y dplyr.
library(dplyr)
library(readxl)
sdg <- read_xlsx("SDR 2021 - Database.xlsx", sheet = 4)Si visualizamos los datos del objeto sdg, veremos que tenemos 193 observaciones (es decir, 193 países) y 125 variables.
sdg
## # A tibble: 193 × 125
## Country Cod…¹ Country Regio…² Popul…³ Pover…⁴ Pover…⁵ Pover…⁶ Preva…⁷ Preva…⁸
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 AFG Afghan… E. Eur… 3.89e7 NA NA NA 29.9 38.2
## 2 ALB Albania E. Eur… 2.88e6 0.16 8.5 NA 3.6 11.3
## 3 DZA Algeria MENA 4.39e7 0.37 2.89 NA 2.8 11.7
## 4 AND Andorra E. Eur… 7.73e4 NA NA NA 1.17 2.58
## 5 AGO Angola Africa 3.29e7 53.8 75.7 NA 18.6 37.6
## 6 ATG Antigu… LAC 9.79e4 NA NA NA 1.17 2.58
## 7 ARG Argent… LAC 4.52e7 0.86 3.52 NA 3.8 7.9
## 8 ARM Armenia E. Eur… 2.96e6 0.83 6.17 NA 2.6 9.4
## 9 AUS Austra… OECD 2.55e7 0.2 0.26 12.4 2.5 2
## 10 AUT Austria OECD 9.01e6 0.28 0.35 9.4 2.5 2.58
## # … with 183 more rows, 116 more variables:
## # `Prevalence of wasting in children under 5 years of age (%)` <dbl>,
## # `Prevalence of obesity, BMI ≥ 30 (% of adult population)` <dbl>,
## # `Human Trophic Level (best 2-3 worst)` <dbl>,
## # `Cereal yield (tonnes per hectare of harvested land)` <dbl>,
## # `Sustainable Nitrogen Management Index (best 0-1.41 worst)` <dbl>,
## # `Yield gap closure (% of potential yield)` <dbl>, …Para visualizarlas mejor, recomendamos utilizar glimpse().
glimpse(sdg)Si nos interesa algún indicador concreto, podemos observar algunas de sus características como:
- La media:
mean(). - El valor máximo
max(). - El valor mínimo
min().
Por ejemplo:
mean(sdg$`Poverty headcount ratio at $1.90/day (%)`, na.rm = T)
## [1] 13.35112Si queremos incluir una tabla que resuma los indicadores, podemos hacerlo así:
- Ponemos cada indicador dentro de
select(), separados por comas. - Cada indicador lo ponemos en este formato:
`nombre_corto = `Nombre largo` - Con
head(10), pedimos solo las 10 primeras observaciones.
sdg |>
select(Country,
pop = `Population in 2020`,
htl = `Human Trophic Level (best 2-3 worst)`,
traffic = `Traffic deaths (per 100,000 population)`) |>
head(10) |>
knitr::kable()| Country | pop | htl | traffic |
|---|---|---|---|
| Afghanistan | 38928341 | 2.190 | 15.86 |
| Albania | 2877800 | 2.383 | 11.70 |
| Algeria | 43851043 | 2.199 | 20.90 |
| Andorra | 77265 | NA | NA |
| Angola | 32866268 | 2.131 | 26.13 |
| Antigua and Barbuda | 97928 | 2.418 | 0.00 |
| Argentina | 45195777 | 2.405 | 14.06 |
| Armenia | 2963234 | 2.280 | 19.95 |
| Australia | 25499881 | 2.468 | 4.94 |
| Austria | 9006400 | 2.412 | 4.87 |
En este caso, incluya un pequeño libro de códigos que indique qué es cada variable. Simplemente, con poner qué equivale cada variable es suficiente. Ejemplo:
- País: Country
- Pob: Population in 2020`
- HTL: Human Trophic Level (best 2-3 worst)
- Tráfico: Traffic deaths (per 100,000 population)
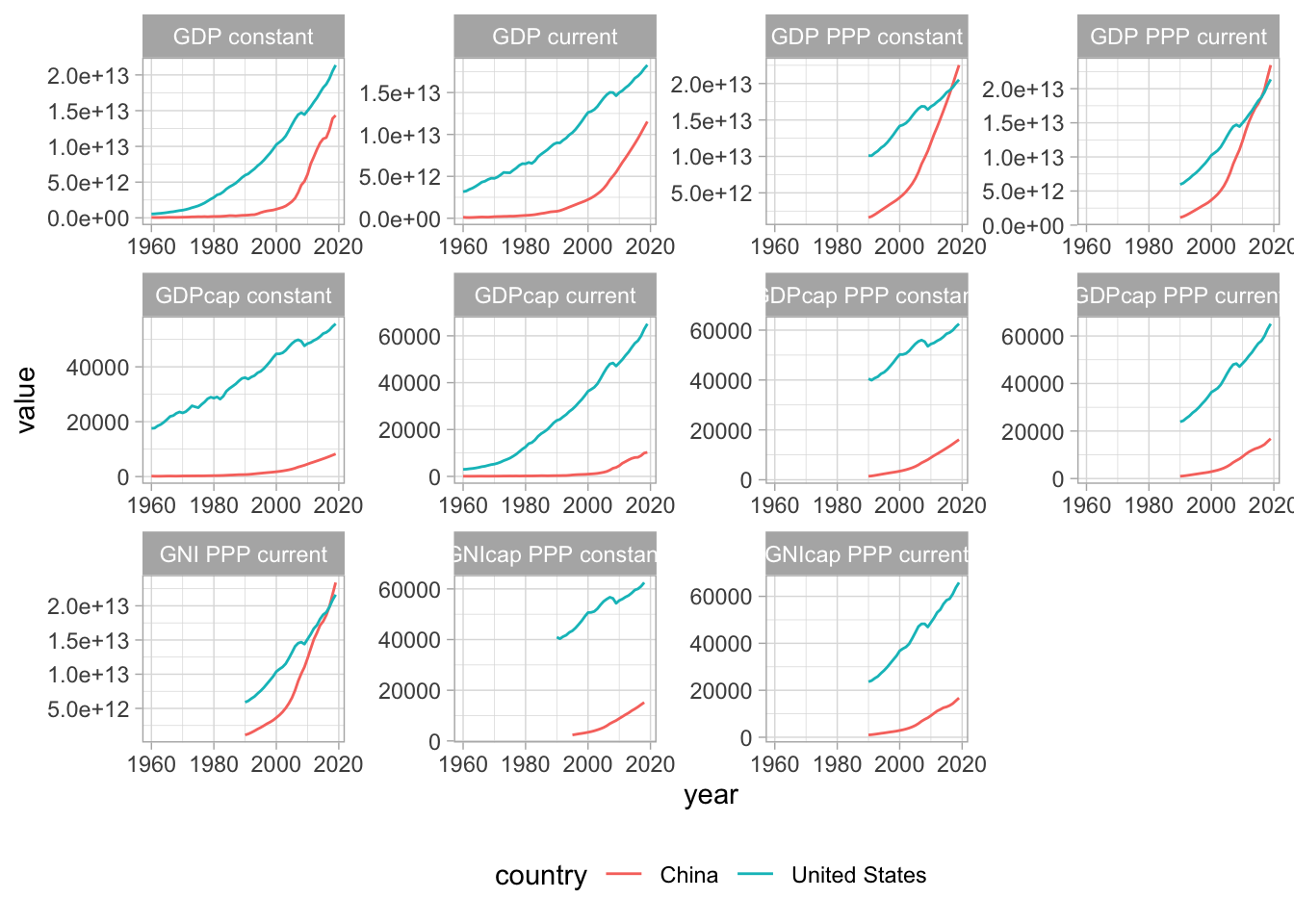
PIB
Identifica todos los problemas entre concepto y medición en este twit.
Carai com perjudiquen l'economia els governs d'esquerres llatinoamericans... #Bolívia pic.twitter.com/mDwI2IF6ep
— Roger Tugas Vilardell 📊 (@rogertugas) October 20, 2020
La Paridad de Poder de Compra
El coste de cortarse el pelo es un buen indicador del coste de la vida en una ciudad:
Evidentemente, en Oslo llevaría el pelo más largo que lo que lo llevo aquí.
— Manuel Hidalgo (@Manuj_Hidalgo) June 28, 2020
Paridad de poder adquisitivo por ciudades en un grafico pic.twitter.com/i1xUUCIHs0
Logaritmo
La escala logarítmica se utiliza en una variable numérica por principalmente dos motivos, uno empírico y uno teórico:
- Empírico: Para representar mejor los valores de la distribución cuando los valores están concentrados en el extremo inferior. Diremos que este tipo de distribución tiene una asimetría negativa).
- Teórico: En el caso de variables como el PIB per cápita, para representar mejor la diferencia en los efectos que tiene una unidad adicional en los valores bajos y los valores altos de la distribución.
Significado empírico del logaritmo
Para conocer el significado empírico del logaritmo, cargaremos las librerías tidyverse y gapminder.
library(tidyverse)
library(gapminder)El marco de datos gapminder contiene información sobre el PIB per cápita, la esperanza de vida y la población de la mayoría de países del mundo. Buena parte de las variables numéricas, como la esperanza de vida, suelen tener un dibujo similar al que vemos en la Figura (fig:gap-normal). La mayoría de las observaciones están ubicadas más o menos en el centro de la distribución. En cambio, existen algunas variables, como el PIB per cápita, que tienen una distribución asimétrica: la mayor parte de los valores están ubicados en un extremo de la distribución mientras que sólo unos pocos casos se encuentran en el otro extremo. En el gráfico observamos cómo la mayoría de países se encuentra en valores muy bajos (piensa que hay datos de los años 50 y 60, cuando prácticamente todos los países eran pobres). Sin embargo, hay muy pocos valores por encima de 30.000.
gapminder %>%
pivot_longer(c(lifeExp, gdpPercap), "vars") %>%
ggplot(aes(x = value)) +
geom_histogram(alpha = 0.4) +
facet_wrap(.~ vars, scales = "free") +
theme_bw()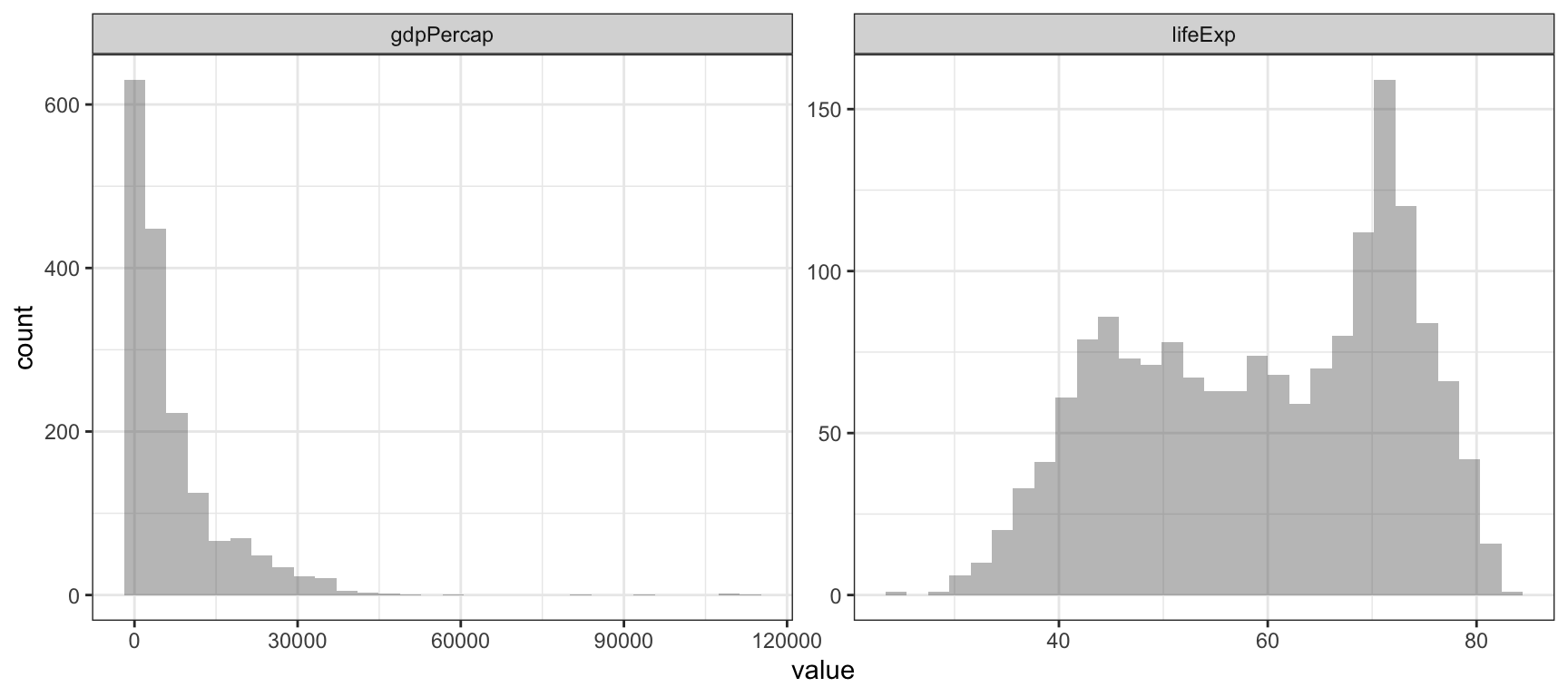
Figure 1: Distribució del PIB per càpita i l’esperança de vida mundial
Cuando tenemos asimetría negativa, en la que la mayor parte de las observaciones están concentradas en valores bajos, utilizaremos el logaritmo para conseguir que la variable tome forma de una distribución normal. com/understanding-the-68-95-99-7-rule-for-a-normal-distribution-b7b7cbf760c2){target=“_blank”}. Si aplicamos el logaritmo a los datos de PIB per cápita del gráfico anterior, obtendremos la Figura 2.
gapminder %>%
ggplot(aes(x = log10(gdpPercap))) +
geom_histogram(alpha = 0.4) +
theme_bw()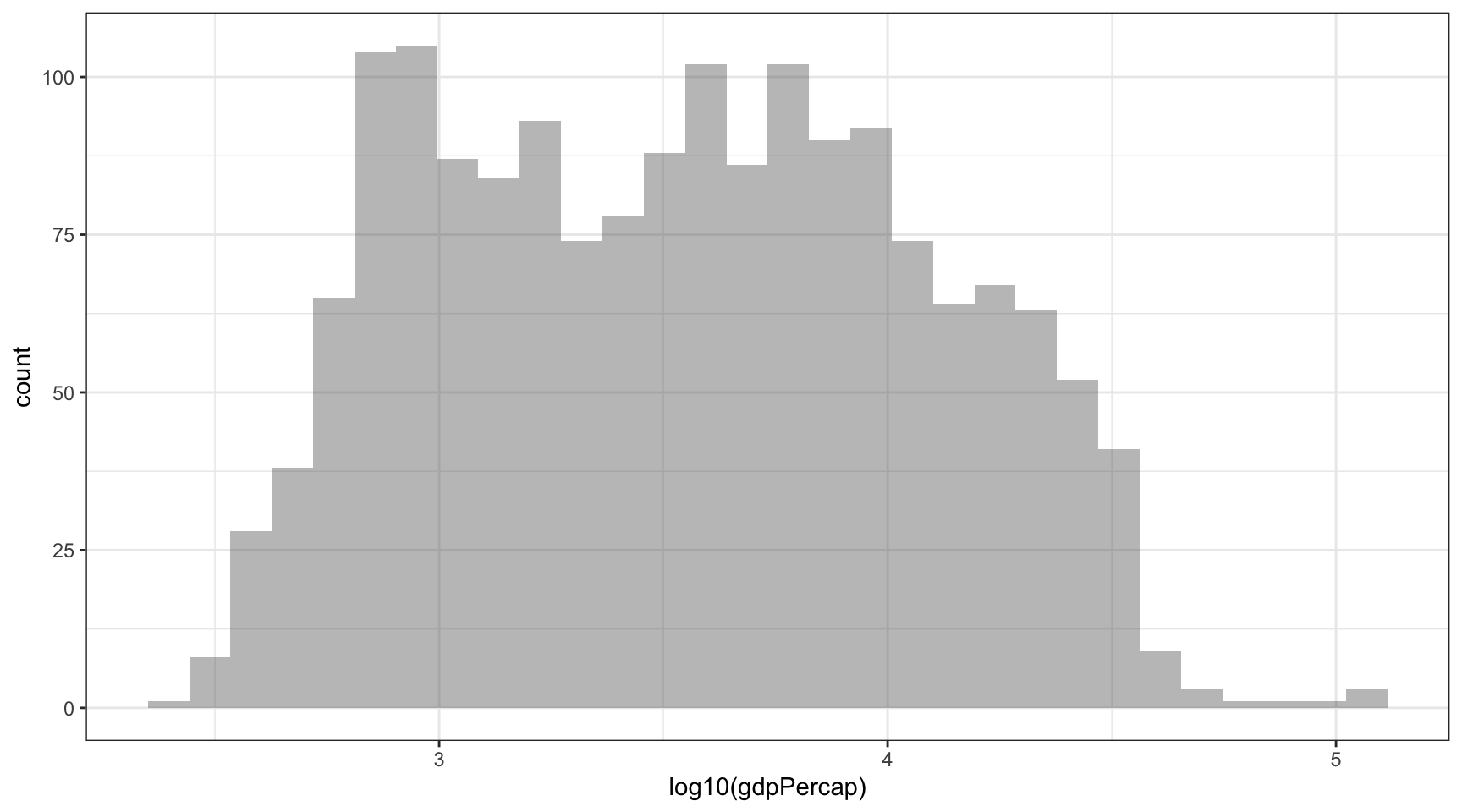
Figure 2: Distribució del PIB per càpita mundial a escala logarítmica
Con el logaritmo conseguimos modificar la forma de la distribución, de modo que podemos representar más nítidamente los casos que existen en los valores bajos. Una de las complicaciones de aplicar el logaritmo es la interpretación de estos nuevos valores, pero por suerte interpretar el logaritmo con base 10 puede resultar relativamente sencillo.
Ejercicio 1. En la Figura 2 hemos aplicado el logaritmo con base 10. Busca cómo interpretarlo y responde:
- ¿Qué valores de PIB per cápita representan los números 3, 4 y 5 del eje horizontal? ¿Por qué no aparece el número 2?
- ¿En qué punto aproximado en valores de PIB per cápita tenemos más casos? ¿Podíamos responder a esta pregunta con el gráfico de la Figura 1?
- ¿Qué tipo de distribución tenemos ahora en este gráfico?
Significado teórico del logaritmo
Aplicar el logaritmo neperiano en el PIB per cápita va muy ligado a las teorías utilitaristas. Existe cierto consenso entre los economistas de que los ingresos tienen efectos marginales decrecientes en el bienestar de las personas. Es decir, una persona pobre disfrutará mucho más de 10 euros adicionales que si estos mismos 10 euros se los damos a una persona rica. El uso del logaritmo sobre el PIB per cápita reproduce esta lógica, ya que enfatizará las variaciones en los niveles bajos de la distribución y reducirá las variaciones en los niveles altos.
Lo veremos con un ejemplo ilustrativo con el marco de datos utility, que observamos en la Tabla 1. En la primera columna income hemos ubicado varios tramos de renta de una persona, empezando por 500 euros y terminando con 45.000. En la segunda columna wellbeing hemos creado una escala de bienestar, que responde a la pregunta: ¿qué bienestar tiene usted en escala de 1 a 10? Puesto que asumimos que ambas variables crecen de forma lineal, en cada incremento de nivel de renta se traducirá en un incremento de un punto en la escala de bienestar. Por ejemplo, si pasamos de ganar 500 a ganar 5.000 euros pasaremos de un bienestar 1 a un bienestar 2. Del mismo modo, si pasamos de 32.000 a 36.500 euros pasaremos de bienestar 8 a bienestar 9. En ambos casos, un incremento en 4.500 euros supone un incremento en un punto en la escala de bienestar.
utility <- tibble(income = seq(500,45000, 4500),
wellbeing = 1:10)| income | wellbeing |
|---|---|
| 500 | 1 |
| 5000 | 2 |
| 9500 | 3 |
| 14000 | 4 |
| 18500 | 5 |
| 23000 | 6 |
| 27500 | 7 |
| 32000 | 8 |
| 36500 | 9 |
| 41000 | 10 |
Un utilitarista nos diría que la mesa que acabamos de construir es errónea. Un aumento de ingresos en niveles bajos de renta se traduce en un aumento mucho más pronunciado en la escala de bienestar que un aumento de igual cantidad en niveles altos. Es por ello, que en la siguiente Figura (fig:log-utility) hemos deformado esta relación. El logaritmo representa ahora mejor la relación entre ingreso y bienestar. En niveles bajos, un aumento de renta se traduce en un aumento muy importante del bienestar. Por el contrario, a niveles altos, un aumento de renta se traduce en un aumento muy pequeño en bienestar.
utility %>%
mutate(wellbeing_log = log10(wellbeing)) %>%
pivot_longer(wellbeing:wellbeing_log, "vars") %>%
ggplot(aes(x = income, y = value)) +
geom_line() +
facet_wrap(.~vars, scales = "free")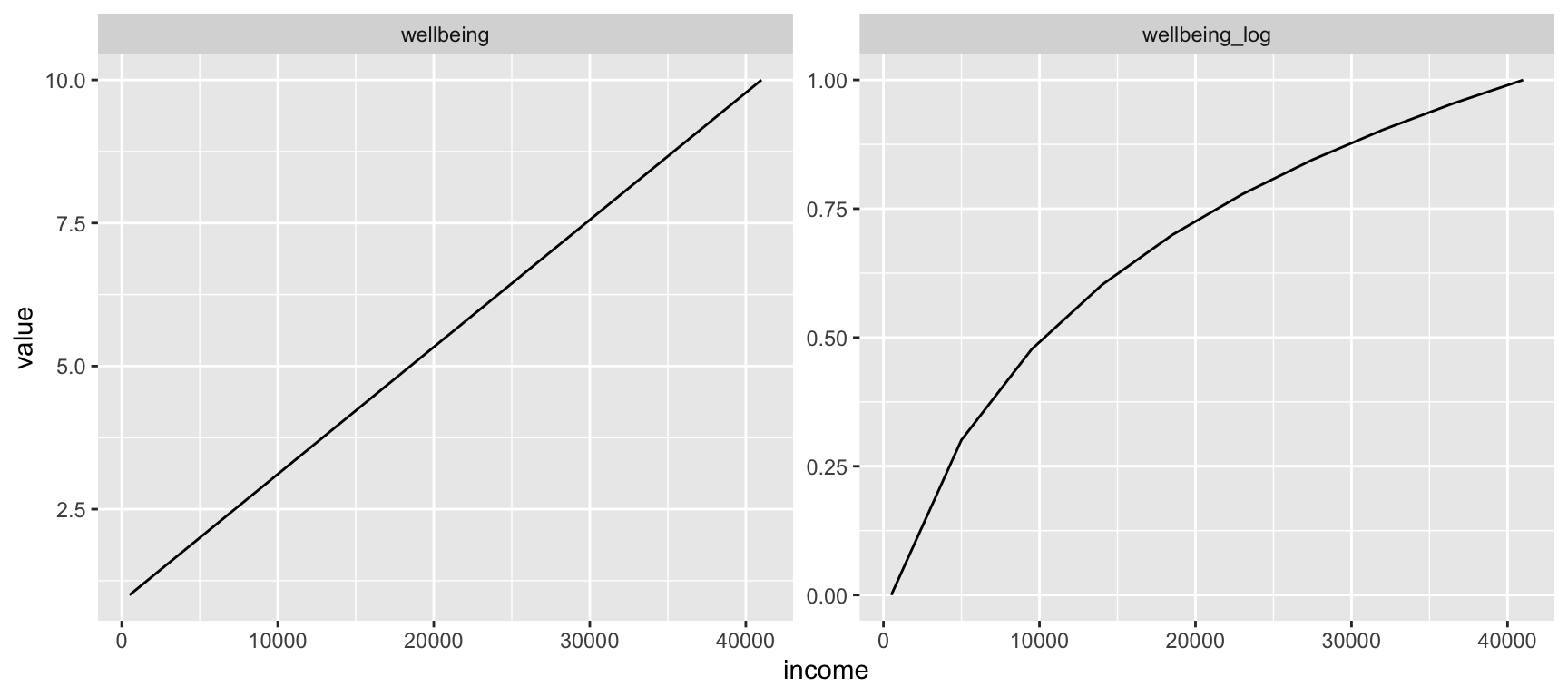
Figure 3: Relació entre renda i benestar
La relación entre renta y bienestar no es lineal, como muestra el gráfico de la izquierda. La relación toma una forma más bien similar al gráfico de la izquierda, donde hemos aplicado el logaritmo con base 10. El logaritmo se utiliza para reflejar la relación entre los ingresos y muchos fenómenos socioeconómicos, como el bienestar o la esperanza de vida . Sin ir más lejos, el Índice de Desarrollo Humano utiliza el logaritmo “para reflejar los rendimientos decrecientes de transformar los ingresos en capacidades humanas. En otras palabras, las personas no necesitan excesivos recursos financieros para asegurarse un estándar de vida decente” (UNDP 1990, 12; ver también Haq 1999, 49). - [x] Más información: The Society Pages
Big Data
El Big Data ha cambiado nuestras vidas. Podemos utilizar muchos datos de forma masiva gracias a las nuevas tecnologías. Por ejemplo, podemos saber muchas cosas del comportamiento de las personas sólo con una simple búsqueda en Google Trends. ¿Cuándo han tenido más interés el ajedrez en los últimos años? Podemos pensar que las búsquedas de la palabra ‘chess’ en Google puede corresponder al interés por el ajedrez que ha tenido a la población mundial en los últimos años:
Ejercicio 2. Intenta, mediante Big Data, responder a las siguientes preguntas:
- ¿A qué corresponden los picos del gráfico?
- ¿En qué país europeo hay más preocupación por Siria?
- ¿Cómo de popular ha sido Kamala Harris en la política americana?
- El gobierno de Ecuador está pensando en abrir una aerolínea y pretende establecer una vuelo directo con España. ¿Recomendaría establecer una conexión con Madrid o con Barcelona?
- Asesorar a un político que realiza una visita a Brasil. En la fiesta después del meeting, ¿pondría música de Metallica o de Bon Jovi?
- ¿Cómo de bien servirían las palabras ‘trump’ y ‘biden’ para predecir al ganador en cada estado norteamericano en las elecciones presidenciales de 2020? ¿Y ‘republican party’ y ‘democratic party’? ¿Se te ocurren dos palabras que ayuden a predecir de forma más cuidadosa el voto?