Mesures d'anàlisi univariant
En aquest apartat aprendrem a sintetitzar variables numèricament. Això significa resumir el contingut d’una variable en un o pocs nombres.
- Si és una variable categòrica, podem saber quina quantitat d’observacions tenim a cada categoria o quin és el percentatge de valors d’una categoria sobre el total d’observacions. Utilitzarem una taula de freqüències.
- Si és una variable numèrica, ens interessarà saber quin és el centre o la dispersió de la distribució.
També treballarem amb gapminder, pel que haurem de carregar els següents paquets:
#recordeu que els paquets han d'estar prèviament instal·lats
library(gapminder)
library(dplyr)
library(ggplot2)
library(tidyr)Taula de freqüències
Com sabeu, no podem fer gaires operacions amb els valors d’una variable categòrica. Principalment, ens podem fer dues preguntes:
- Quantes observacions hi ha a cada categoria? Per tant, amb
table()demanarem una taula que recompti el nombre d’observacions.
table(gapminder$continent)##
## Africa Americas Asia Europe Oceania
## 624 300 396 360 24- Quin percentatge d’observacions tenim a cada categoria? Per tant, afegirem
prop.table()i arrodonirem els decimals ambround()per saber quin percentatge per saber la proporció d’observacions a cada categoria.
round(prop.table(table(gapminder$continent)), 2)##
## Africa Americas Asia Europe Oceania
## 0.37 0.18 0.23 0.21 0.01Mesures de centralitat
Amb una variable numèrica sí que podem fer operacions més complexes. Com que els valors són ordenables i tenen un sentit numèric, podem veure quin valor es troba en el centre de la distribució. El problema és que no hi ha una única manera de determinar un centre, sinó que ho podem fer principalment de tres maneres:
- La mitjana
- La mediana
- La moda
Suposem que volem conèixer la mitjana, la mediana i la moda del següent vector:
c(65, 67, 68, 73, 74, 77, 80, 80, 80, 82, 83)La mitjana s’obté sumant tots els valors i repartint-los a parts iguals entre ells. La mitjana del vector és 75.36. El mateix procediment que veiem a continuació es pot obtenir amb la funció mean().
sum(c(65, 67, 69, 73, 74, 77, 80, 80, 80, 81, 83)) / 11## [1] 75.36364A continuació veiem la distribució del PIB per càpita per països el 2002. La mitjana, representada amb una línia blava, es troba al voltant de 10.000 dòlars.
gap02_mean <- gapminder %>%
filter(year == 2002) %>%
ggplot(aes(x = gdpPercap)) +
geom_histogram(aes(y=..density..), colour= "white", fill= "lightblue2", bins = 40) +
geom_density(col = "darkslateblue", size = 1.2, fill = "darksalmon", alpha = 0.2) +
geom_vline(aes(xintercept = mean(gdpPercap)), color = "blue", linetype = "dashed", size = 2) +
theme_classic()
gap02_mean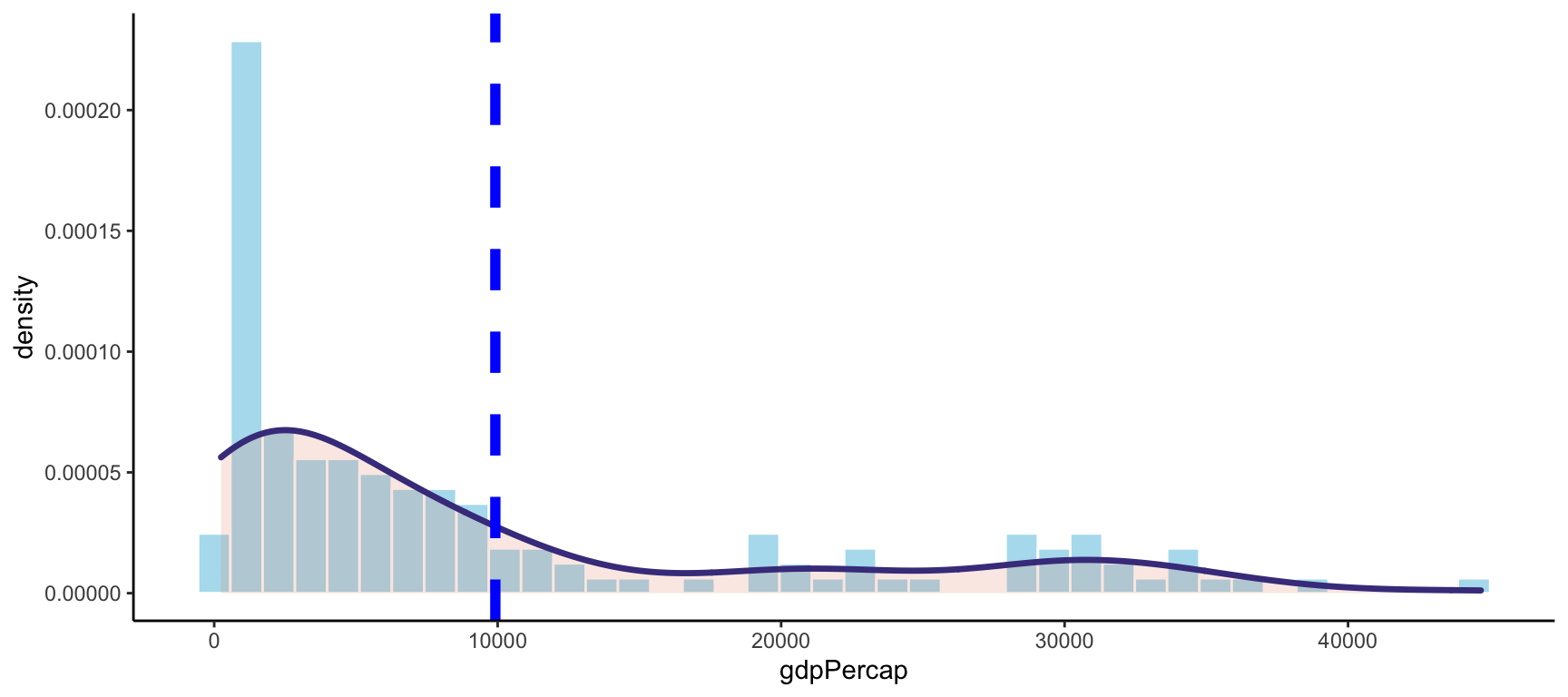
Figure 1: Mitjana del PIB per càpita el 2002
La mediana s’obté ordenant tots els valors de la distribució de menor a mejor i observant quin és el valor que talla la distribució en exactament dues meitats. L’obtindrem amb la funció median(). En el cas anterior veiem com el valor que està just al mig de la distribució ordenada és 77.
median(c(65, 67, 68, 73, 74, 77, 80, 80, 80, 82, 83))## [1] 77Si representem gràficament la distribució del PIB per càpita el 2002, veiem com es troba lleugerament per sobre els 5.000 dòlars. Això significa que el 2002 el país que tenia exactament el mateix nombre de països amb el PIB per càpita inferior i amb el PIB per càpita superior se situava al voltant dels 5.000 dòlars.
gap02_mean +
geom_vline(aes(xintercept = median(gdpPercap)),
color="greenyellow", linetype = "dashed", size = 2)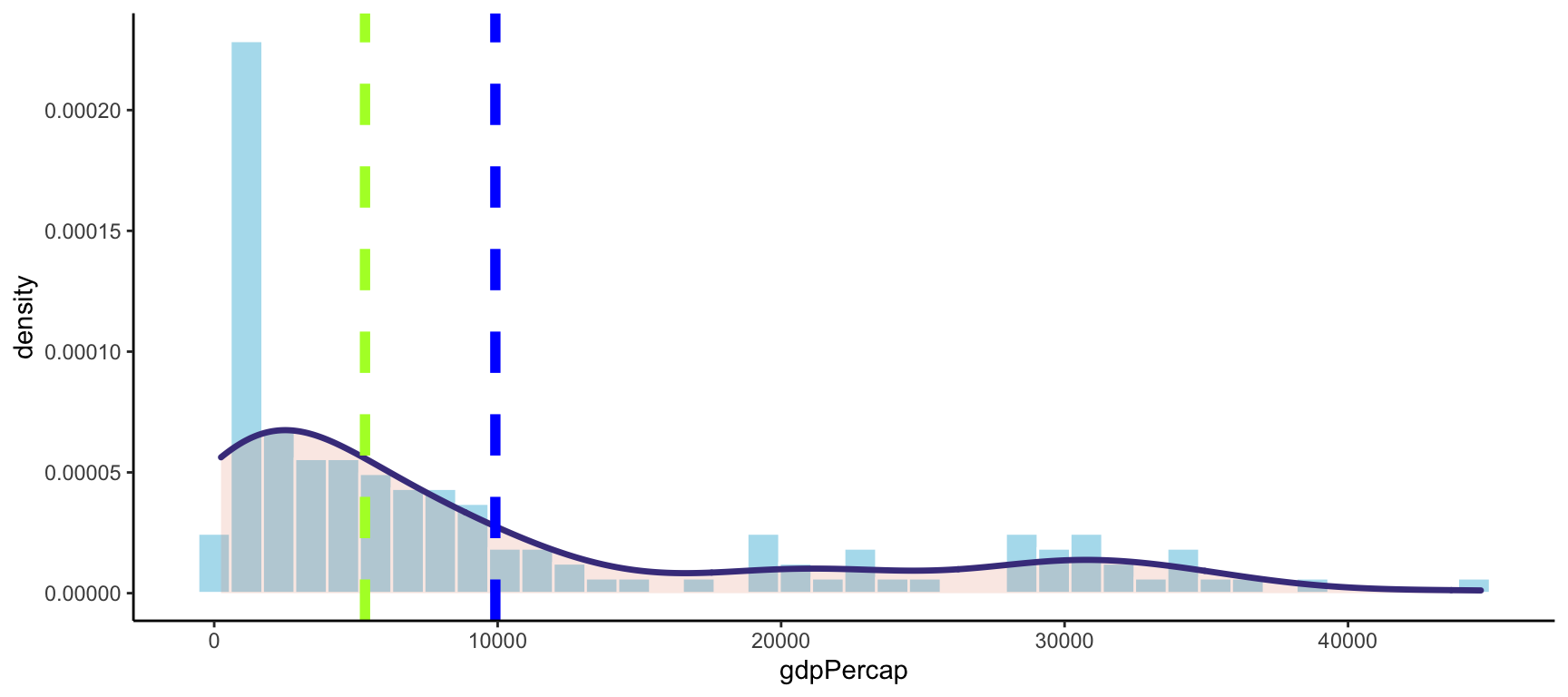
Figure 2: Mediana del PIB per càpita el 2002
La moda és el valor més freqüent d’una distribució. Aquest valor és molt senzill d’obtenir per variables categòriques amb la funció table(), com hem vist anteriorment. En canvi, és més complicat d’obtenir amb variables numèriques, ja que els valors d’una variable numèrica no s’acostumen a repetir (i en cas que, per exemple, dos països tinguin exactament el mateix PIB tampoc té gaire interès des d’un punt de vista descriptiu). És més adequat buscar la moda a partir dels intervals. Per exemple, en l’anterior distribució la moda se situa aproximadament entre els 1.000 i els 2.000 dòlars per càpita.
En el cas de variables numèriques discretes, com el següent vector, sí que és més fàcil d’obtenir la moda. Veiem com el número més repetir és el 80.
c(65, 67, 68, 73, 74, 77, 80, 80, 80, 82, 83)En una distribució hi pot haver més d’una moda. Distingirem entre:
- Unimodal
- Bimodal
- Multimodal
- Uniforme
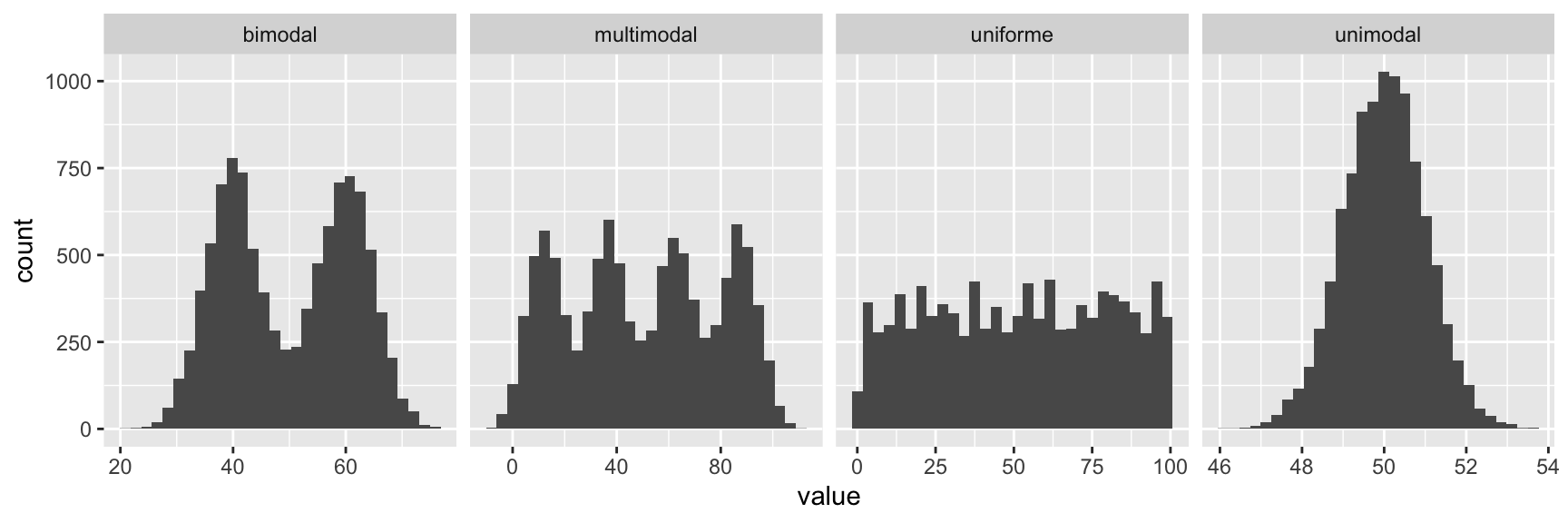
Tipus de distribucions
Les distribucions també reben diferents nomenclatures en funció de la ubicació de la moda, la mediana i la mitjana:
- Asimetria positiva: La mitjana és inferior a la mediana.
- Asimetria negativa: La mitjana és superior a la mediana.
- Distribució simètrica: La moda, la mediana i la mitjana ocupen una posició similar.
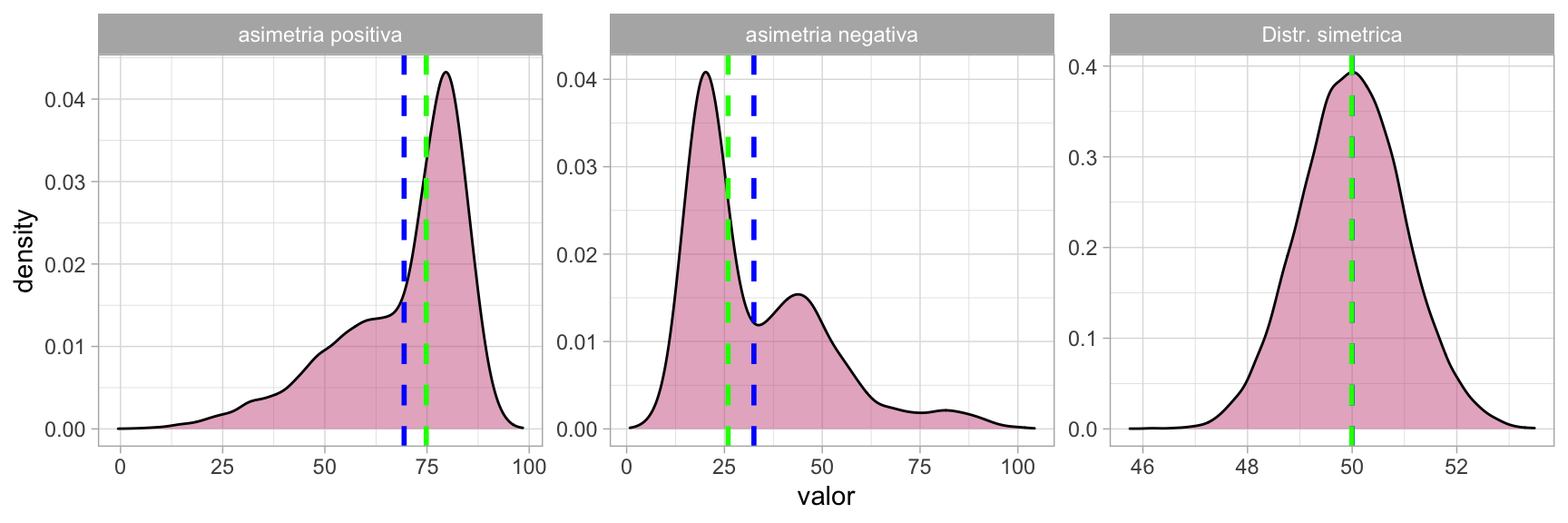
Mesures de dispersió
Per determinar la dispersió d’una variable numèrica hi ha diversos procediments:
- El rang
- El rang interquartílic
- La desviació típica
El rang és simplement la diferència entre el valor més alt i el més baix d’una distribució.
diff(range(gapminder$gdpPercap))## [1] 113282max(gapminder$gdpPercap) - min(gapminder$gdpPercap)## [1] 113282El rang interquartílic (també dit IQR) mira la diferència entre els percentils 25 i 75. Ho podem obtenim amb la funció IQR() o bé a través de quantile().
IQR(gapminder$gdpPercap)## [1] 8123.402quantile(gapminder$gdpPercap, 0.75) - quantile(gapminder$gdpPercap, 0.25)## 75%
## 8123.402La desviació típica mira com de molt els valors estan allunyats de la mitjana. La podem obtenir amb la funció sd(). Com a exemple, hem creat el vector dev_ex1.
dev_ex1 <- c(4, 6, 5, 8, 5, 3, 5, 6, 4, 1)El procediment pel qual s’obté és el següent:
diff_mitjana <- dev_ex1 - mean(dev_ex1) #Calculem la diferència de cada valor de la distribució amb la mitjana.
diff_quadrat <- (diff_mitjana)^2 #Elevem al quadrat, de manera que convertim en positius els números negatius
suma_diff_quadrat <- sum(diff_quadrat) #Sumem tots els valors
variancia <- suma_diff_quadrat/(length(dev_ex1) - 1) #Dividim pel nombre de casos menys 1
desviacio_tipica <- sqrt(variancia) #Fem l'arrel quadradaMasterclass
En el següent vídeo podeu veure una aplicació pràctica de l’anàlisi univariant. L’analista de dades David Robinson, en una de les seves sessions de TidyTuesday fa una masterclass analitzant la base de dades que registra les violacions de diferents països de la Unió Europea de la General Data Protection Regulation (GDPR).
Font: DatacampAnnex
Codi taula de freqüències
wb <- data.frame(country = c("Antigua and Barbuda", "Belice", "Costa Rica", "Dominica",
"Dominican Republic", "El Salvador", "Guyana", "Guatemala",
"Haiti", "Honduras", "Jamaica", "Nicaragua", "Panama", "Surinam",
"Trinidad and Tobago"),
income = factor(c("high", "upper-middle", "upper-middle", "upper-middle",
"upper-middle", "lower-middle", "upper-middle", "upper-middle",
"low", "lower-middle", "upper-middle", "lower-middle", "high",
"upper-middle", "high")),
stringsAsFactors = FALSE)Codi tipus de moda
data.frame(unimodal = rnorm(10000, 50), #unimodal
bimodal = c(rnorm(5000, 60, 5), rnorm(5000, 40, 5)), #bimodal
multimodal = c(rnorm(2500, 12, 7), rnorm(2500, 37, 7), rnorm(2500, 63, 7), rnorm(2500, 88, 7)),#multimodal
uniforme = rep(sample(1:100, 5000, replace = T), 2)) %>%
gather(tipo) %>%
ggplot(aes(x = value)) +
geom_histogram() +
facet_grid(. ~ tipo, scale = "free")Codi simetria
simetria <- data.frame(simetrica = rnorm(10000, 50),
dre = c(rnorm(5500, 80, 5), rnorm(2500, 65, 9),
rnorm(1500, 50, 9), rnorm(500, 30, 9)),
esq = c(rnorm(5500, 20, 5), rnorm(2500, 40, 9),
rnorm(1500, 50, 9), rnorm(500, 80, 9)))
distr_ty <- gather(simetria, tipo, valor)
mm <- distr_ty %>%
group_by(tipo) %>%
summarize(grp.mean = mean(valor),
grp.median = median(valor))
ggplot(distr_ty, aes(x = valor)) +
geom_density(fill = "hotpink3", alpha = 0.5) +
facet_wrap(. ~ tipo, scale = "free",
labeller = as_labeller(c(dre = "asimetria positiva",
esq = "asimetria negativa",
simetrica = "Distr. simetrica"))) +
geom_vline(data = mm, aes(xintercept=grp.mean),
color="blue", linetype="dashed", size=1) +
geom_vline(data = mm, aes(xintercept=grp.median),
color="green", linetype="dashed", size=1) +
theme_light()