Relació entre variables numèriques
Aquest apartat es construeix a partir dels apartats anteriors, on hem explorat els paquets unvotes (Voeten 2017) i la Democracy Dataset (DD) (Cheibub, Gandhi, and Vreeland 2010). A continuació hi afegirem indicadors del World Development Indicadors (WDI) i el paquet gapminder.
#recordeu que els paquets han d'estar prèviament instal·lats
library(dplyr)
library(tidyr)
library(ggplot2)
library(readr)
library(gapminder)
library(wbstats)
library(unvotes)Quan vulguem mirar l’associació entre dues variables numèriques utilitzarem la regressió. En primer lloc explicarem una regressió simple i més endavant veurem la regressió múltiple.
Regressió simple
Hi ha cinc aspectes principals que ens poden interessar de la relació entre dues variables numèriques:
- Forma: El dibuix que fa la relació entre
xiy. - Força: Com de perfecte és el dibuix format per punts.
- Direcció: Si les variables es mouen en la mateixa direcció (relació positiva) o en direcció oposada (negativa).
- Significació: La probabilitat que realment la relació sigui inexistent.
- Casos extrems: Si algunes observacions estan molt allunyades de la resta.
En aquest apartat volem mirar com és l’associació entre el PIB per càpita i l’esperança de vida després de la Guerra Freda. Per a això utilitzarem una versió simplificada de gapminder. Eliminarem també un cas extrem.
gap90 <- gapminder %>%
filter(year > 1990, lifeExp > 25) #eliminem un cas extremCASOS EXTREMS: En ocasions, alguns casos estan molt allunyats de la resta de valors de la distribució i podem considerar eliminar-los perquè, pensem, poden venir explicats per altres factors molt diferents. Quin és el cas extrem que hem eliminat?
gapminder[which(gapminder$lifeExp < 25),]Visualitzar
La manera de visualitzar una relació entre variables numèriques és per mitjà d’un diagrama de dispersió, que cridarem per mitjà de la geometria geom_point(). La relació que tenen els punts entre sí ens l’indicarà la recta de regressió, que és la línia recta que passa el més a prop possible de tots els punts. La cridarem amb geom_smooth(method = "lm").
gap90 %>%
ggplot(aes(gdpPercap, lifeExp)) +
geom_point(aes(col = continent), alpha = 0.7) +
geom_smooth(method = "lm", se = FALSE) +
theme_minimal() +
theme(legend.position = "bottom", legend.title = NULL)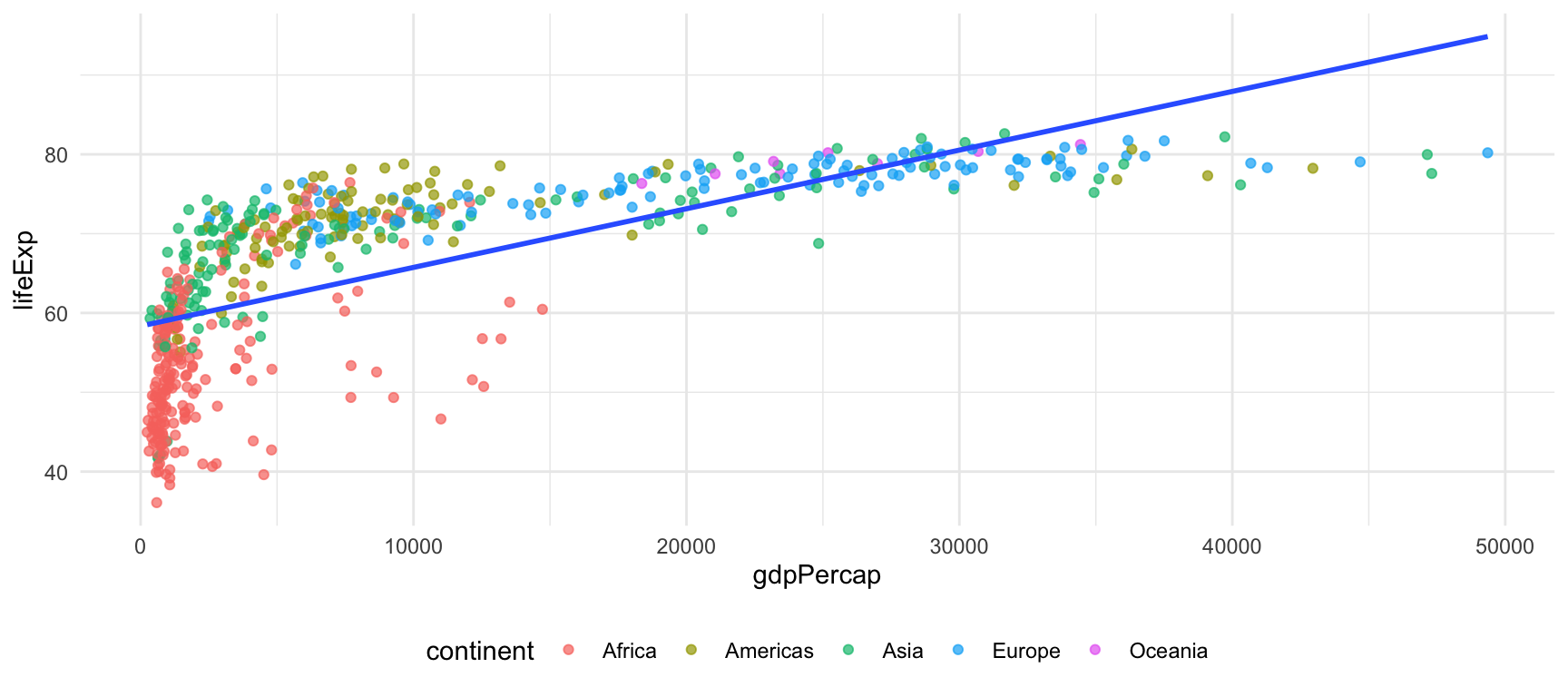
Fixeu-vos que amb aquesta visualització sabem que:
- La forma no és lineal.
- És una relació positiva i forta.
- Podríem considerar que alguns països africans són casos extrems.
La recta de regressió també es diu recta OLS (Ordinary Least Squares). Un altre tipus de recta és la LOESS (Locally Estimated Scatterplot Smoothing), que podem cridar si no introduïm cap argument a dins de geom_smooth().
Quantificar
Encara que visualment ja ens podem fer una idea de la força, la direcció i fins i tot de la significació d’una relació, ens serà molt més fàcil comparar relacions si obtenim aquests paràmetres d’una manera numèrica.
- El coeficient de correlació és un nombre que varia entre -1 a 1 i s’obté a través de la funció
cor(). El signe mostra si la relació és positiva o negativa. La proximitat amb 1 ens indica la força de la relació.
Podem obtenim el coeficient de correlació entre dues variables numèriques, per exemple, indicant cor(gap90$gdpPercap, gap90$lifeExp). Una manera més sofisticada per obtenir i comparar múltiples coeficients és la següent:
gapminder %>%
filter(year %in% c(1957, 1967, 1977, 1977, 1987, 1997, 2007),
continent %in% c("Europe", "Africa", "Americas")) %>%
group_by(continent, year) %>%
summarize(cor = cor(lifeExp, gdpPercap),
N = n()) %>%
spread(year, cor)| continent | N | 1957 | 1967 | 1977 | 1987 | 1997 | 2007 |
|---|---|---|---|---|---|---|---|
| Africa | 52 | 0.2589616 | 0.2490682 | 0.3478392 | 0.6277603 | 0.5643816 | 0.3847152 |
| Americas | 25 | 0.6232590 | 0.6066095 | 0.5912833 | 0.6174131 | 0.6054986 | 0.5909661 |
| Europe | 30 | 0.7389486 | 0.7135078 | 0.7342168 | 0.7291457 | 0.8275159 | 0.8499711 |
- El coeficient de determinació, també dit R2, és un nombre que varia entre 0 i 1 i ens indica quina proporció de la variació en la variable dependent podem explicar amb la variació dels valors de la variable independent. S’obté, simplement, elevant el quadrat el coeficient de correlació.
cor(x, y)^2Modelar
Modelar significa crear una fórmula a partir de les dades existents que ens permeti predir el valor d’una variable si coneixem el valor de l’altra variable. De fet, ja hem vist un model anterioment: la recta OLS. Amb aquesta recta podem predir els valors d’y si coneixem els valors d’x.
Per crear un model lineal necessitem saber:
- La constant: El valor d’
yquanxés zero. - La inclinació: Quant creix o decreix
ysi augmentem una unitat d’x.
Podem conèixer aquests valors amb la fórmula lm(formula = y ~ x, data = dataframe) i després demanar un summary(). Provem-ho amb un model en què la variable dependent sigui l’esperança de vida i la independent el PIB per càpita:
summary(lm(formula = lifeExp ~ gdpPercap, data = gap90))##
## Call:
## lm(formula = lifeExp ~ gdpPercap, data = gap90)
##
## Residuals:
## Min 1Q Median 3Q Max
## -22.699 -5.740 1.236 6.764 14.119
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.835e+01 4.741e-01 123.08 <2e-16 ***
## gdpPercap 7.395e-04 3.239e-05 22.83 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 8.435 on 565 degrees of freedom
## Multiple R-squared: 0.4799, Adjusted R-squared: 0.479
## F-statistic: 521.3 on 1 and 565 DF, p-value: < 2.2e-16En els resultats observem el següent:
- Constant: En un hipotètic país amb el PIB per càpita igual a zero, l’esperança de vida seria de 58.35 anys (ens movem en termes hipotètics, ja sabem que és impossible que hi hagi un país on l’ingrés mitjà sigui zero).
- Pendent: Quan augmentem el PIB per càpita en una unitat (per tant, l’augmentem un dòlar), l’esperança de vida creix 0.0007395 anys.
- Significació: La relació és estadísticament significativa, tal com ens mostra el p-valor (
Pr(>|t|)) de<2e-16(també ens ho mostren els tres asteriscos). - Determinació: Sabent el PUB per càpita d’un país, tenim un 48% de probabilitats d’encertar l’esperança de vida. Ho veiem en la
Multiple R-squared. - Model: D’acord amb els paràmetres que hem obtingut, el model predictiu de l’esperança de vida en base als valors del PIB per càpita és el següent:
x <- 0
5.835e+01 + 7.395e-04 * xÉs important recalcar que el PIB per càpita té una distribució asimètrica i, per tant, milloraríem el model si hi apliquéssim el logaritme. No obstant, per facilitar la interpretació de les dades, en aquest exercici no l’hem aplicat.
Regressió múltiple
Una regressió múltiple és, en curt, un model de regressió amb vàries variables independents. En la funció lm() només ens cal afegir la variable zi tantes variables com calguin.
summary(lm(formula = y ~ x + z, data = model))La hipòtesi que volem comprovar és que ser una democràcia (x) té un efecte negatiu sobre el vot afirmatiu a l’AGNU (y). Pensem, però, que potser això està determinat per:
- El nivell de desenvolupament del país (
w). - La proporció de democràcies a l’assemblea (
z).
Primer de tot, preparem les dades:
- WDI: Obtenim informació del PIB per càpita anual a partir de 1946 (recordem que gapminder només podem saber el PIB per càpita cada cinc anys) a través del paquet
wbstats(Piburn 2020).
wbstats::wb_search("gdp per capita.*constant")## # A tibble: 7 x 3
## indicator_id indicator indicator_desc
## <chr> <chr> <chr>
## 1 5.51.01.10.gdp Per capita GDP growth GDP per capita is the sum of gross v…
## 2 6.0.GDPpc_cons… GDP per capita, PPP (co… GDP per capita based on purchasing p…
## 3 NY.GDP.PCAP.KD GDP per capita (constan… GDP per capita is gross domestic pro…
## 4 NY.GDP.PCAP.KD… GDP per capita growth (… Annual percentage growth rate of GDP…
## 5 NY.GDP.PCAP.KN GDP per capita (constan… GDP per capita is gross domestic pro…
## 6 NY.GDP.PCAP.PP… GDP per capita, PPP (co… GDP per capita based on purchasing p…
## 7 NY.GDP.PCAP.PP… GDP per capita, PPP ann… Annual percentage growth rate of GDP…gdp_wb <- wbstats::wb_data(indicator = "NY.GDP.PCAP.PP.KD", start_date = 1946, end_date = 2018)
gdp_wdi <- gdp_wb %>%
transmute(iso2c, year = as.numeric(date),
country, gdpcap = NY.GDP.PCAP.PP.KD) %>%
as_tibble()- UN Votes: Obtenim informació del percentatge de vots afirmatius de cada país i, més endavant, de la proporció anual de vots favorables a l’AGNU.
- DD Dataset: Obtenir informació binària de la presència de democràcia a cada país.
# Obtenim el percentatge de vots favorables de cada país
un_year_vote <- un_roll_calls %>%
separate(date, "year", extra = "drop") %>%
inner_join(un_votes) %>%
mutate(year = as.numeric(year),
vote = if_else(vote == "yes", 1, 0)) %>%
group_by(country, country_code, year) %>%
summarize(vote = mean(vote))
# Afegim el marc de dades DDdata amb l'indicador dicotòmic de democràcia
un_vote_dem <- un_year_vote %>%
inner_join(DDdata, by = c("country_code" = "iso2c", "year" = "year")) %>%
select(country = country.x, country_code, year, vote, democracy)
# Obtenim la proporció anual de vots favorables a l'AGNU
un_prop <- un_vote_dem %>%
group_by(year) %>%
summarize(unga_prop = mean(democracy))
#Afegim les dades de PIB per càpita de WDI
un_wdi <- un_vote_dem %>%
left_join(un_prop, by = "year") %>%
inner_join(gdp_wdi, by = c("country_code" = "iso2c", "year" = "year")) %>%
select(country = country.x, year, vote, democracy,
gdpcap, unga_prop) %>%
filter(gdpcap != is.na(gdpcap))El marc de dades un_wdi ens queda de la següent manera:
| country_code | country | year | vote | democracy | gdpcap | unga_prop |
|---|---|---|---|---|---|---|
| AF | Afghanistan | 2008 | 0.9722222 | 0 | 1484.114 | 0.6137566 |
| AL | Albania | 2008 | 0.6533333 | 1 | 9912.577 | 0.6137566 |
| DZ | Algeria | 2008 | 0.9054054 | 0 | 10796.903 | 0.6137566 |
| AO | Angola | 2008 | 0.9436620 | 0 | 7864.375 | 0.6137566 |
| AG | Antigua and Barbuda | 2008 | 0.9324324 | 1 | 23131.578 | 0.6137566 |
| AR | Argentina | 2008 | 0.8684211 | 1 | 23103.457 | 0.6137566 |
| AM | Armenia | 2008 | 0.7702703 | 1 | 10467.530 | 0.6137566 |
| AU | Australia | 2008 | 0.5394737 | 1 | 44835.361 | 0.6137566 |
| AT | Austria | 2008 | 0.6578947 | 1 | 53089.876 | 0.6137566 |
| AZ | Azerbaijan | 2008 | 0.9066667 | 0 | 12903.152 | 0.6137566 |
| BS | Bahamas | 2008 | 0.9014085 | 1 | 38746.784 | 0.6137566 |
| BH | Bahrain | 2008 | 0.8684211 | 0 | 46408.832 | 0.6137566 |
| BD | Bangladesh | 2008 | 0.9200000 | 0 | 2659.049 | 0.6137566 |
| BB | Barbados | 2008 | 0.9189189 | 1 | 16946.671 | 0.6137566 |
| BY | Belarus | 2008 | 0.8513514 | 0 | 15942.898 | 0.6137566 |
| BE | Belgium | 2008 | 0.6315789 | 1 | 48422.578 | 0.6137566 |
| BZ | Belize | 2008 | 0.9365079 | 1 | 7426.891 | 0.6137566 |
| BJ | Benin | 2008 | 0.9264706 | 1 | 2738.194 | 0.6137566 |
| BT | Bhutan | 2008 | 0.8985507 | 1 | 6995.779 | 0.6137566 |
| BO | Bolivia (Plurinational State of) | 2008 | 0.9189189 | 1 | 6351.226 | 0.6137566 |
A continuació creem el model de regressió amb les variables corresponents i demanem el sumari:
summary(lm(formula = vote ~ democracy + gdpcap + unga_prop, data = un_wdi))##
## Call:
## lm(formula = vote ~ democracy + gdpcap + unga_prop, data = un_wdi)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.91949 -0.07551 0.01963 0.10436 0.35445
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.011e+00 4.971e-02 20.337 <2e-16 ***
## democracy -9.609e-02 5.264e-03 -18.254 <2e-16 ***
## gdpcap -2.579e-06 1.421e-07 -18.153 <2e-16 ***
## unga_prop -1.600e-01 8.779e-02 -1.822 0.0685 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1418 on 3092 degrees of freedom
## Multiple R-squared: 0.2115, Adjusted R-squared: 0.2108
## F-statistic: 276.5 on 3 and 3092 DF, p-value: < 2.2e-16Observant els resultats arribem a les següents conclusions:
- Ser una democràcia (
x) té un efecte negatiu i significatiu sobre el vot afirmatiu a l’AGNU (y) fins i tot quan controlem per les dues variables alternatives. - El nivell de desenvolupament del país (
w) també afecta de manera negativa i significativa el vot favorable a l’AGNU. - La proporció de democràcies a l’assemblea (
z), en canvi, no sembla afectar el vot favorable a l’AGNU. - Si coneixem els valors de les variables independents tenim un 21% de probabilitats d’encertar la variable dependent (certament, no és un percentatge gaire elevat, pel qual faríem bé de buscar altres variables que ens proporcionin un model millor).