Medidas de análisis univariante
En este apartado aprenderemos a sintetizar variables numéricamente. Esto significa resumir el contenido de una variable en uno o pocos números.
- Si es una variable categórica, podemos saber qué cantidad de observaciones tenemos cada categoría o cuál es el porcentaje de valores de una categoría sobre el total de observaciones. Utilizaremos una tabla de frecuencias.
- Si es una variable numérica, nos interesará saber cuál es el centro o la dispersión de la distribución.
También trabajaremos con gapminder, por lo que tendremos que cargar los siguientes paquetes:
#recordad que todos los paquetes deben estar previamente instalados
library(gapminder)
library(dplyr)
library(ggplot2)
library(tidyr)Tabla de frecuencias
Como sabéis, no podemos hacer muchas operaciones con los valores de una variable categórica. Principalmente, nos podemos hacer dos preguntas:
- ¿Cuántas observaciones hay en cada categoría? Por lo tanto, con
table()pedirá una tabla que recuente el número de observaciones.
table(gapminder$continent)##
## Africa Americas Asia Europe Oceania
## 624 300 396 360 24- ¿Qué porcentaje de observaciones tenemos en cada categoría? Por lo tanto, añadiremos
prop.table()y redondear los decimales conround()para saber el porcentaje para saber la proporción de observaciones cada categoría.
round(prop.table(table(gapminder$continent)), 2)##
## Africa Americas Asia Europe Oceania
## 0.37 0.18 0.23 0.21 0.01Medidas de centralidad
Con una variable numérica sí podemos hacer operaciones más complejas. Como los valores son ordenables y tienen un sentido numérico, podemos ver qué valor se encuentra en el centro de la distribución. El problema es que no hay una única manera de determinar un centro, sino que lo podemos hacer principalmente de tres maneras:
- La media
- La mediana
- La moda
Supongamos que queremos conocer la media, la mediana y la moda del siguiente vector:
c(65, 67, 68, 73, 74, 77, 80, 80, 80, 82, 83)La media obtiene sumando todos los valores y repartiendo a partes iguales entre ellos. La media del vector es 75.36. El mismo procedimiento que vemos a continuación se puede obtener con la función mean().
sum(c(65, 67, 69, 73, 74, 77, 80, 80, 80, 81, 83)) / 11## [1] 75.36364A continuación vemos la distribución del PIB per cápita por países en 2002. La media, representada con una línea azul, se encuentra alrededor de 10.000 dólares.
gap02_mean <- gapminder %>%
filter(year == 2002) %>%
ggplot(aes(x = gdpPercap)) +
geom_histogram(aes(y=..density..), colour= "white", fill= "lightblue2", bins = 40) +
geom_density(col = "darkslateblue", size = 1.2, fill = "darksalmon", alpha = 0.2) +
geom_vline(aes(xintercept = mean(gdpPercap)), color = "blue", linetype = "dashed", size = 2) +
theme_classic()
gap02_mean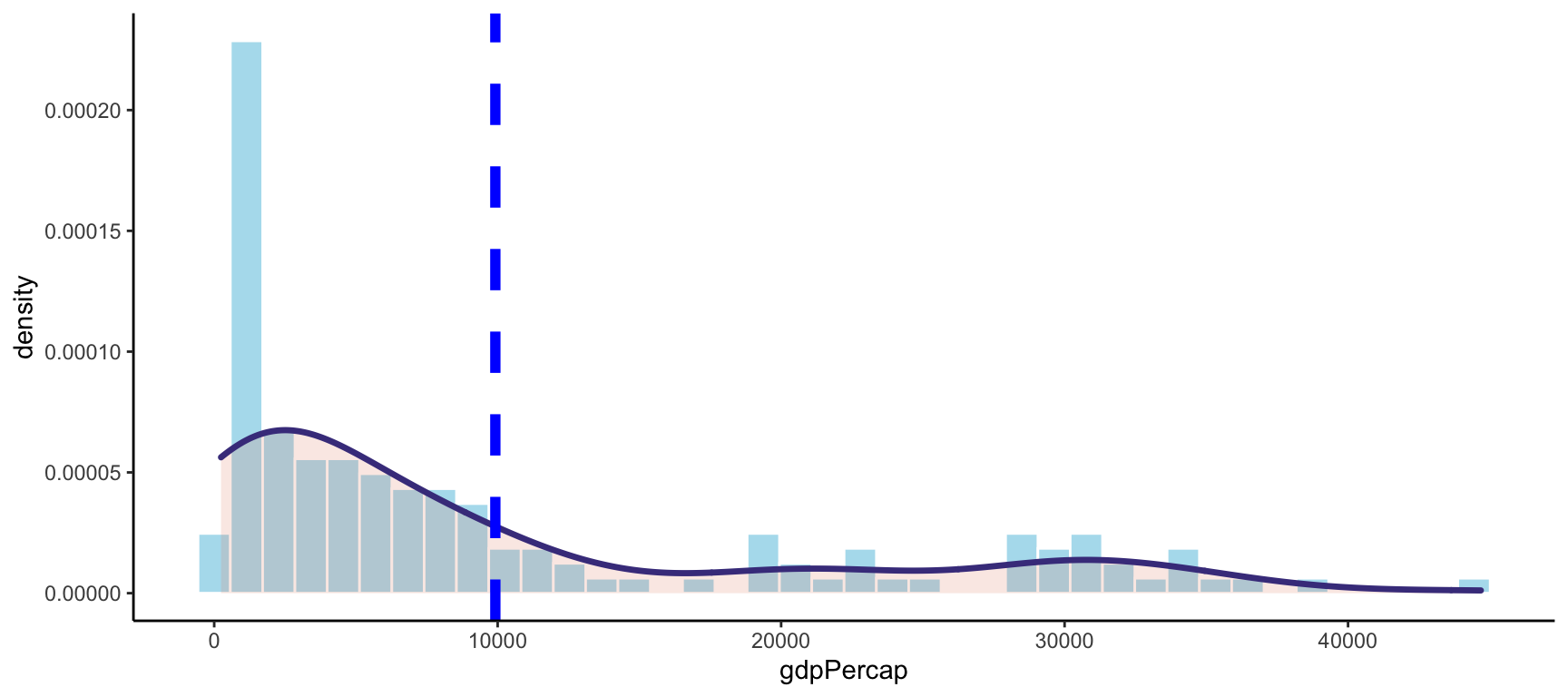
Figure 1: Mitjana del PIB per càpita el 2002
La mediana se obtiene ordenando todos los valores de la distribución de menor a mejor y observando cuál es el valor que corta la distribución en exactamente dos mitades. La obtendremos con la función median(). En el caso anterior vemos como el valor que está justo en medio de la distribución ordenada es 77.
median(c(65, 67, 68, 73, 74, 77, 80, 80, 80, 82, 83))## [1] 77Si representamos gráficamente la distribución del PIB per cápita en 2002, vemos cómo se encuentra ligeramente por encima de los 5.000 dólares. Esto significa que en 2002 el país que tenía exactamente el mismo número de países con el PIB per cápita inferior y con el PIB per cápita superior se situaba en torno a los 5.000 dólares.
gap02_mean +
geom_vline(aes(xintercept = median(gdpPercap)),
color="greenyellow", linetype = "dashed", size = 2)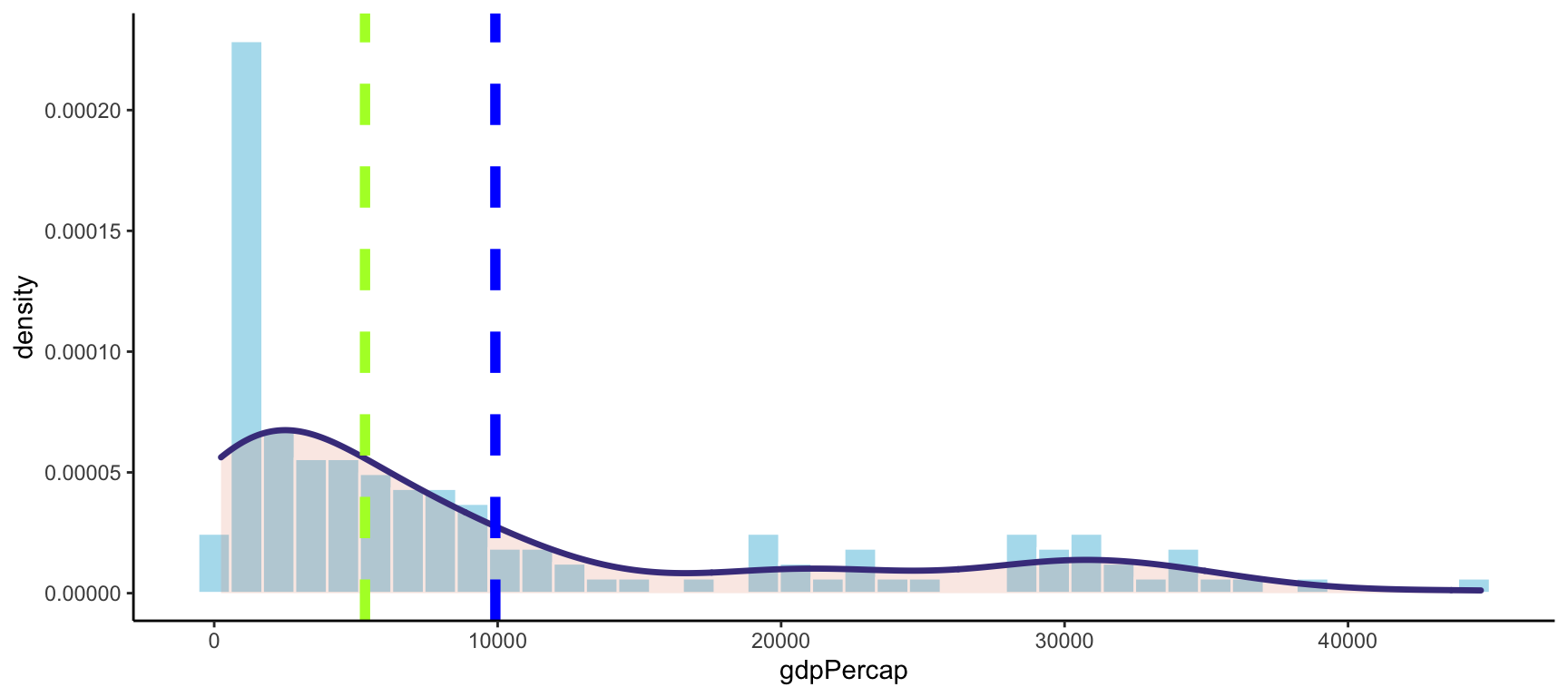
Figure 2: Mediana del PIB per càpita el 2002
La moda es el valor más frecuente de una distribución. Este valor es muy sencillo de obtener para variables categóricas con la función table(), como hemos visto anteriormente. En cambio, es más complicado de obtener con variables numéricas, ya que los valores de una variable numérica no se suelen repetir (y en caso de que, por ejemplo, dos países tengan exactamente el mismo PIB tampoco tiene mucho interés desde un punto de vista descriptivo). Es más adecuado buscar la moda a partir de los intervalos. Por ejemplo, en la anterior distribución la moda se sitúa aproximadamente entre los 1.000 y los 2.000 dólares per cápita.
En el caso de variables numéricas discretas, como el siguiente vector, sí que es más fácil de obtener la moda. Vemos como el número más repetido es el 80.
c(65, 67, 68, 73, 74, 77, 80, 80, 80, 82, 83)En una distribución puede haber más de una moda. Distinguiremos entre:
- Unimodal
- Bimodal
- Multimodal
- Uniforme
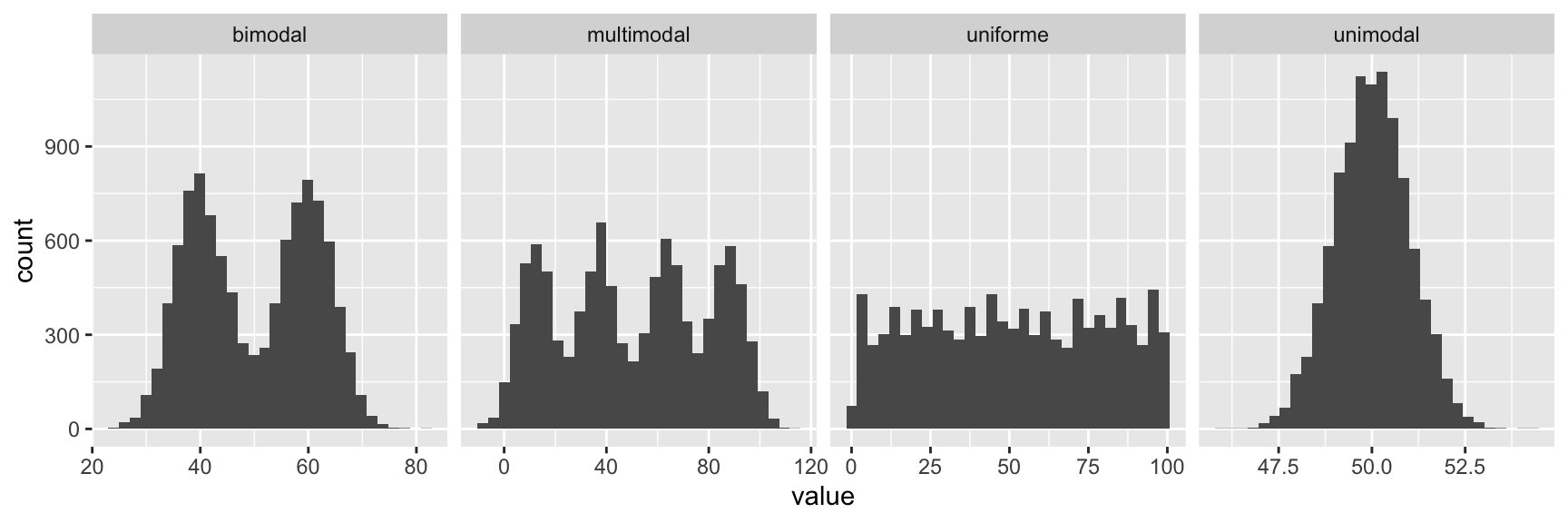
Tipos de distribuciones
Las distribuciones también reciben diferentes nomenclaturas en función de la ubicación de la moda, la mediana y la media:
- Asimetría positiva: La media es inferior a la mediana.
- Asimetría negativa: La media es superior a la mediana.
- Distribución simétrica: La moda, la mediana y la media ocupan una posición similar.
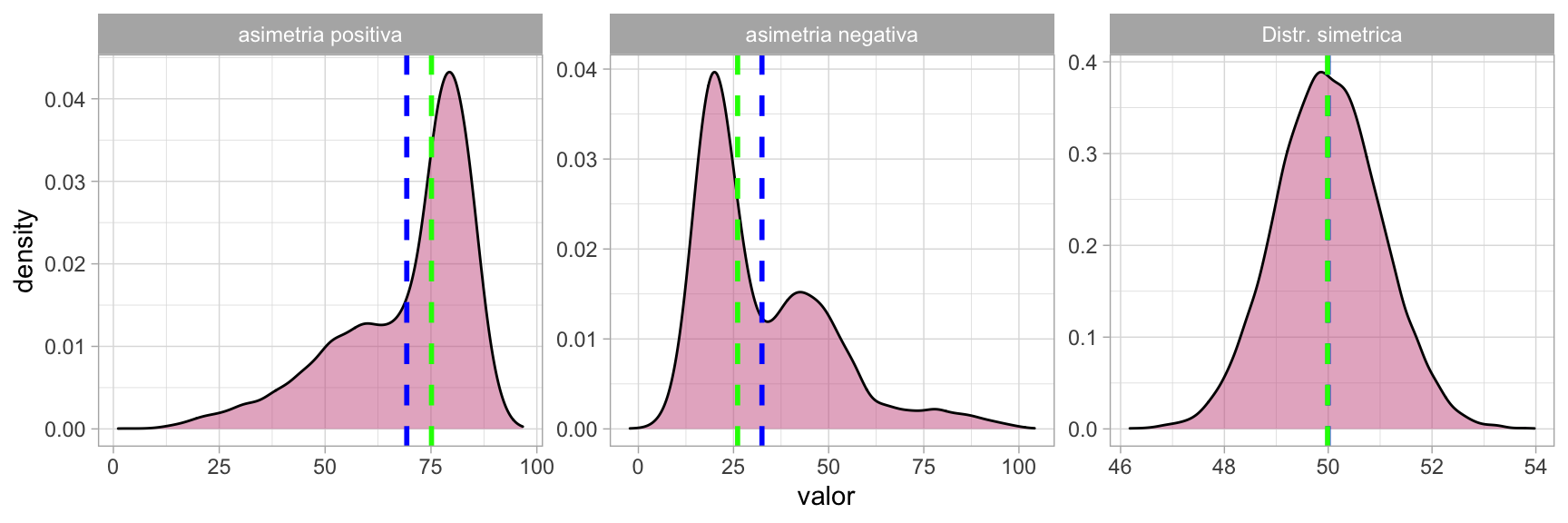
Medidas de dispersión
Para determinar la dispersión de una variable numérica hay varios procedimientos:
- El rango
- El rango intercuartílico
- La desviación típica
El rango es simplemente la diferencia entre el valor más alto y el más bajo de una distribución.
diff(range(gapminder$gdpPercap))## [1] 113282max(gapminder$gdpPercap) - min(gapminder$gdpPercap)## [1] 113282El rango intercuartílico (también dicho IQR) mira la diferencia entre los percentiles 25 y 75. Lo podemos obtenemos con la función IQR() o bien a través de quantile().
IQR(gapminder$gdpPercap)## [1] 8123.402quantile(gapminder$gdpPercap, 0.75) - quantile(gapminder$gdpPercap, 0.25)## 75%
## 8123.402La desviación típica mira hasta qué punto los valores están alejados de la media. La podemos obtener con la función sd(). Como ejemplo, hemos creado el vector dev_ex1.
dev_ex1 <- c(4, 6, 5, 8, 5, 3, 5, 6, 4, 1)El procedimento por el cual se obtiene es el siguiente:
diff_mitjana <- dev_ex1 - mean(dev_ex1) #Calculamos la difernecia de cada valor de la distribución con la media
diff_quadrat <- (diff_mitjana)^2 #Elevamos al cuadrado, de forma que convertimos en positivos los números negativos
suma_diff_quadrat <- sum(diff_quadrat) #Sumamos todos los valores
variancia <- suma_diff_quadrat/(length(dev_ex1) - 1) #Dividimos por el nombre de casos menos 1
desviacio_tipica <- sqrt(variancia) #Hacemos la raíz cuadradaMasterclass
En el siguiente vídeo podéis ver una aplicación práctica del análisis univariante. El analista de datos David Robinson, en una de sus sesiones de TidyTuesday hace una masterclass analizando la base de datos que registra las violaciones de diferentes países de la Unión Europea de la General Data Protection Regulation (GDPR).
Font: DatacampAnnexo
Código tabla de frecuencias
wb <- data.frame(country = c("Antigua and Barbuda", "Belice", "Costa Rica", "Dominica",
"Dominican Republic", "El Salvador", "Guyana", "Guatemala",
"Haiti", "Honduras", "Jamaica", "Nicaragua", "Panama", "Surinam",
"Trinidad and Tobago"),
income = factor(c("high", "upper-middle", "upper-middle", "upper-middle",
"upper-middle", "lower-middle", "upper-middle", "upper-middle",
"low", "lower-middle", "upper-middle", "lower-middle", "high",
"upper-middle", "high")),
stringsAsFactors = FALSE)Código tipo de moda
data.frame(unimodal = rnorm(10000, 50), #unimodal
bimodal = c(rnorm(5000, 60, 5), rnorm(5000, 40, 5)), #bimodal
multimodal = c(rnorm(2500, 12, 7), rnorm(2500, 37, 7), rnorm(2500, 63, 7), rnorm(2500, 88, 7)),#multimodal
uniforme = rep(sample(1:100, 5000, replace = T), 2)) %>%
gather(tipo) %>%
ggplot(aes(x = value)) +
geom_histogram() +
facet_grid(. ~ tipo, scale = "free")Código simetria
simetria <- data.frame(simetrica = rnorm(10000, 50),
dre = c(rnorm(5500, 80, 5), rnorm(2500, 65, 9),
rnorm(1500, 50, 9), rnorm(500, 30, 9)),
esq = c(rnorm(5500, 20, 5), rnorm(2500, 40, 9),
rnorm(1500, 50, 9), rnorm(500, 80, 9)))
distr_ty <- gather(simetria, tipo, valor)
mm <- distr_ty %>%
group_by(tipo) %>%
summarize(grp.mean = mean(valor),
grp.median = median(valor))
ggplot(distr_ty, aes(x = valor)) +
geom_density(fill = "hotpink3", alpha = 0.5) +
facet_wrap(. ~ tipo, scale = "free",
labeller = as_labeller(c(dre = "asimetria positiva",
esq = "asimetria negativa",
simetrica = "Distr. simetrica"))) +
geom_vline(data = mm, aes(xintercept=grp.mean),
color="blue", linetype="dashed", size=1) +
geom_vline(data = mm, aes(xintercept=grp.median),
color="green", linetype="dashed", size=1) +
theme_light()