Relación entre variables categoricas
En este apartado aprenderemos a analizar la asociación entre dos variables categóricas. Hay cuatro tipos de asociaciones y cada una se analiza con una técnica diferente:
- Tabla de contingencia: Entre dos variables categóricas.
- Diferencia de medias: Entre una variable categórica independiente y una numérica dependiente.
- Regresión logística: Entre una variable numérica independiente y una categórica dependiente.
- Regresión: Entre dos variables numéricas.
A continuación cargaremos los siguientes paquetes, entre ellos el paquete unvotes (Voeten 2017), de donde sacaremos información sobre sobre las votaciones en la Asamblea General de Naciones Unidas (AGNU). Por eso tendremos que cargar los siguientes paquetes:
#recordad que los paquetes deben estar previamente instalados
library(gapminder)
library(dplyr)
library(ggplot2)
library(DescTools)
library(unvotes)
library(stringr)Tabla de contingencia
La tabla de contingencia es la manera de visualizar la relación entre dos variables categóricas. Si examinamos el marco de datos un_votes, veremos que la variable vote contiene tres valores: yes, no o abstain. Sacaremos la categoría abstain de manera que nos queden sólo yes y no. Nos preguntaremos si Sudán del Sur ha votado diferente que Sudán en materia de desarrollo económico (ec) a partir de la AGNU número 5117, la primera después de la independencia de Sudán del Sur.
sudan_ec_votes <- un_votes %>%
inner_join(un_roll_call_issues) %>%
filter(country %in% c("Sudan", "South Sudan"), rcid >= 5117,
vote != "abstain", short_name == "ec") %>%
select(country, vote) %>%
droplevels()La tabla de contingencia se crea con table(). Podemos ver como Sudán del Sur ha votado 11 veces sí y 1 vez no, mientras que Sudán ha votado 16 veces sí y 3 no.
table(sudan_ec_votes$vote, sudan_ec_votes$country)##
## South Sudan Sudan
## yes 20 34
## no 1 4¿Qué significa en términos relativos? Para descubrirlo tendremos que utilizar la función prop.table() y redondear los resultados porcentuales con round().
round(prop.table(table(sudan_ec_votes$vote, sudan_ec_votes$country), margin = 2) * 100, 2)##
## South Sudan Sudan
## yes 95.24 89.47
## no 4.76 10.53Visualización gráfica
Gráficamente, la forma en que podemos observar las diferencias entre dos variables categóricas es con un diagrama de barras geom_bar().
sudan_ec_votes %>%
ggplot(aes(x = country, fill = vote)) +
geom_bar(position = "fill", width = 0.5) +
scale_fill_brewer(type = "qual", palette = 3) +
theme_minimal()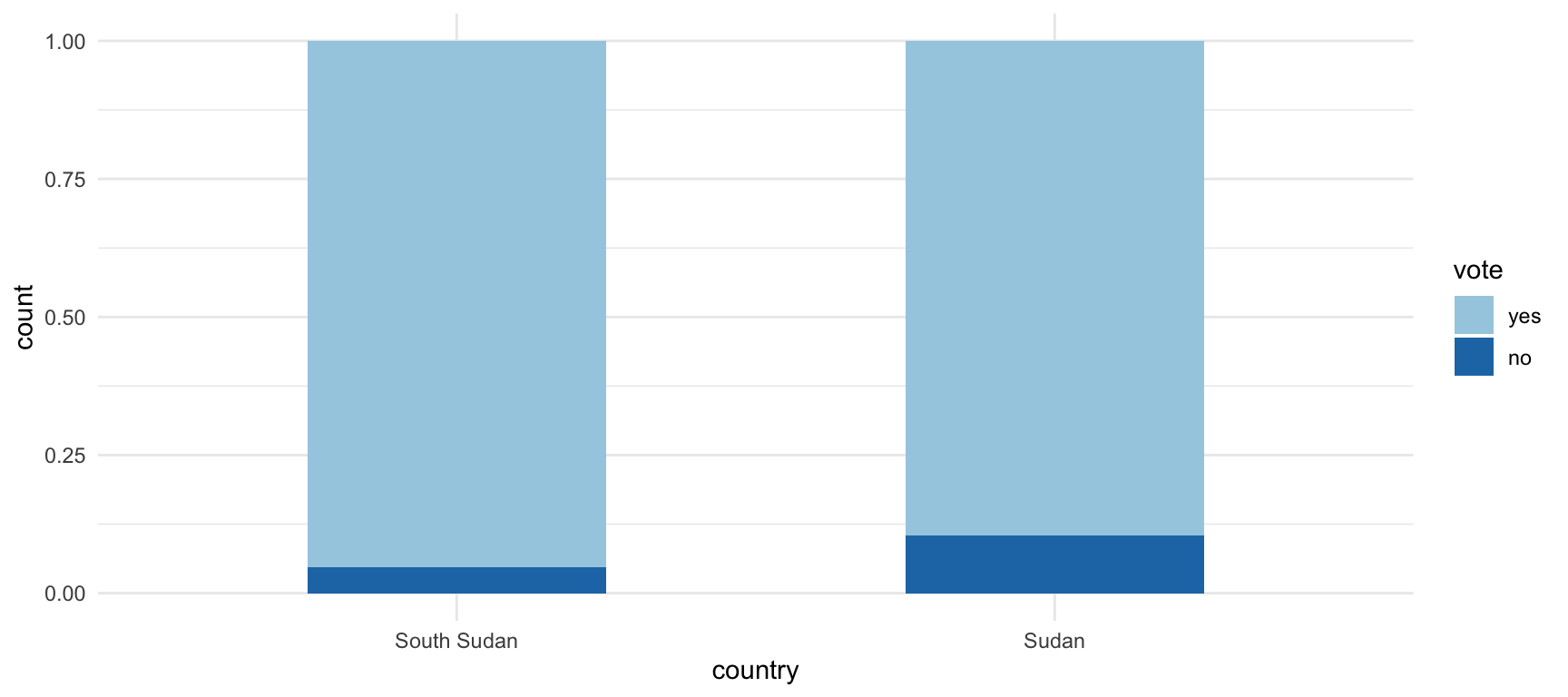
Cuantificar
Principalmente queremos saber dos cosas de esta relación:
- El coeficiente de asociación.
- El test de significación.
El coeficiente de asociación nos mide la fuerza de una relación, como el test de Cramer, que utilizaremos con la función CramerV() que se encuentra en el paquete DescTools. Estos métodos nos permiten saber cómo de bien podemos saber los valores de la variable dependiente si conocemos los valores de la variable dependiente.
CramerV(sudan_ec_votes$vote, sudan_ec_votes$country)## [1] 0.09910019La operación nos devuelve un coeficiente de asociación de Cramer cercano a 0.11. Esto significa que si conocemos los valores de x tenemos un 11% de probabilidades de acertar los valores de y. Ciertamente, no es una probabilidad de acierto muy alta.
El test de significación nos dice qué probabilidad hay de que la hipótesis nula sea cierta y lo obtendremos con el chisq.test().
chisq.test(sudan_ec_votes$vote, sudan_ec_votes$country)##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: sudan_ec_votes$vote and sudan_ec_votes$country
## X-squared = 0.074551, df = 1, p-value = 0.7848Es demasiado probable que la hipótesis nula sea cierta. El resultado debería ser inferior a 0.05 para descartar la hipótesis nula.
Ejercicio: Fijaos con los siguientes códigos y generad las operaciones que se indican a continuación:
- Una tabla de contingencia.
- Una visualización.
- El coeficiente de asociación.
- El test de significación.
Estados Unidos: ¿Hubo diferencia en el voto favorable a la AGNU entre las administraciones Carter y Reagan?
us_un <- un_roll_calls %>%
inner_join(un_votes) %>%
select(-c(country, descr, short)) %>%
filter(country_code == "US", vote != "abstain",
between(date, as.Date("1977-01-20"),
as.Date("1989-01-20"))) %>%
mutate(president = if_else(date < as.Date("1980-01-20"),"Carter", "Reagan"))Israel: ¿Israel vota diferente a la AGNU cuando se tratan o no de temas relacionados con Oriente Medio?
israel_un <- un_votes %>%
inner_join(un_roll_call_issues) %>%
filter(country == "Israel", vote != "abstain") %>%
mutate(me = if_else(short_name == "me", "Middle East", "Other")) %>%
select(me, vote) %>%
droplevels()Estados Unidos - USSR: ¿Votan diferente los Estados Unidos si en el título de la resolución aparece la palabra USSR?
us_ussr_un <- un_roll_calls %>%
mutate(ussr = str_detect(descr, "USSR")) %>%
inner_join(un_votes) %>%
filter(country_code == "US", vote != "abstain") %>%
select(ussr, vote) %>%
droplevels()