4. Altres mesures compostes
Els continguts d’aquesta obra formen part d’un encàrrec d’autoria de la Universitat Oberta de Catalunya (Mas 2020) i estan subjectes a la llicència de Creative Commons CC BY-SA 3.0.

Els índexs compostos segueixen els processos de normalització, ponderació i agregació descrits en l’apartat anterior. Més enllà d’aquesta estructura, existeixen altres tipus de mesures compostes que segueixen una lògica diferent en el seu procés de construcció. No hi ha consens acadèmic en la manera de definir i caracteritzar aquestes mesures. Per exemple, Earl R. Babbie fa la distinció entre índexs i escales, encara que les diferències entre els dos procediments de construcció s’ha anat difuminant durant el pas del temps (Babbie 2013: 198-199). En aquest apartat ens centrarem a explicar dos tipus de mesures compostes que es distingeixen dels índexs pel fet que estan construïdes amb la lògica de conjunts (set theory). Aquesta lògica té la particularitat que els diferents indicadors no s’agrupen mitjançant fórmules aritmètiques o geomètriques, sinó que s’agrupen i ordenen mitjançant condicions de suficiència i necessitat, molt utilitzades en estudis qualitatius i comparats (Goertz and Mahoney 2012; Rihoux and Ragin 2009). El raonament és el següent:
- Necessitat: La condició és necessària per indicar la presència d’un determinat concepte. En altres paraules, el concepte no és present si la condició no és present.
- Suficiència: La condició és suficient per indicar la presència d’un determinat concepte. En altres paraules, quan la condició és present el concepte sempre és present.
Si traduïm el que acabem d’explicar amb alguns exemples:
- Tenir ales és una condició necessària per ser un ocell. Però és una condició suficient? No, els avions tenen ales i no són pas ocells.
- Estar a Escòcia és condició suficient per estar al Regne Unit. Però és necessari? No, podem estar al Regne Unit des de molts altres llocs: des de Gal·les, Manchester o des de la platja de Brighton.
- No presentar-se un examen és condició suficient per suspendre’l. Però és necessària? No, també podem suspendre l’examen si ens presentem però no contestem correctament les preguntes.
- Els astrònoms creuen que la presència d’aigua és una condició necessària per la vida en altres planetes, però és això una condició suficient per la vida? No, també es creu que serien necessaris altres requisits com la llum solar o una temperatura estable.
- Democràcia, Populisme, Guerra, Diplomàcia, Revolució.
- Genocidi, Terrorisme, Organització internacional.
Els criteris de suficiència i necessitat s’il·lustren normalment en una matriu 2x2 com les de la Figura 1. A cada matriu veiem com es relaciona la presència (1) o absència (0) de l’indicador X amb la presència o absència del fenomen Y per establir una condició necessària o suficient.
- A la part esquerra veiem la X és condició necessària per Y quan la X és 0. Llavors, sabem segur que Y no pot ser 1.
- A la part dreta veiem que la X és condició suficient per Y quan la X no és 1. Llavors, sabem que la Y ha de ser per força zero.

Figure 1: Condició suficient i condició necessària | Goertz and Mahoney (2012)
Els dos tipus de mesures compostes que veurem en aquest apartat funcionen amb la lògica de conjunts. Al primer tipus en direm índexs lògics, que construeixen la mesura composta sense seguir cap ordre específic en les seves variables. És a dir, les variables es combinen entre sí sense pressuposar cap tipus de rang entre elles i conformen l’índex final a partit de certes condicions de suficiència i necessitat. Al segon tipus en direm escales –i explicarem exclusivament l’escala de Likert–, que sí que assumeixen un ordre específic entre variables, de manera que els indicadors que componen la mesura segueixen una jerarquia d’intensitat.
En aquest apartat utilitzarem els següents paquets:
library(foreign)
library(dplyr)
library(readr)
library(ggplot2)
library(tidyr)Índexs lògics
Els índexs lògics es podrien considerar, simplement, índexs amb l’única diferència que segueixen un raonament fonamentat amb els conjunts lògics, de manera que els resultats queden ordenats en categories discretes ordenables. Un dels terrenys de la Ciència Política on més s’ha fet servir aquesta lògica ha estat en els estudis de democràcia. Alguns autors defensen que l’existència de democràcia en un determinat país ve condicionada per la presència d’unes determinades condicions, necessàries i en conjunt suficients (Przeworski et al. 2000). Aquest raonament ha donat origen a les classificacions dicotòmiques de democràcia, que estableixen dues categories per determinar si un règim polític és una democràcia (1) o si no ho és (0).
Democracy-Dictatorship dataset
Una de les classificacions més emprades en estudis internacionals és la Democracy-Dictatorship (DD) dataset (Cheibub, Gandhi, and Vreeland 2010). Si consultem el seu llibre de codis, ens trobarem amb la següent Figura 2, que es pot llegir com a: “tindrem presència de democràcia, si la variable exselec és igual o inferior a 2 i la variable legselec és igual a 2 i la variable closed és igual a 2 i la variable dejure és igual a 2 i la variable defacto és igual a 2 i la variable defacto2 és igual a 2 i la variable lparty és igual a 2 i la variable type2 és igual a 0 i la variable incumb és igual a 0.”1

Figure 2: Condicions de democràcia de la DD dataset
Podem descarregar i consultar la base de dades a través del codi que apareix a continuació, a partir del qual hem generat l’objecte dd que representem a la següent Taula 1. Us podeu ajudar dels de la secció Democràcia binària per fer una exploració a fons del marc de dades.
dd <- as_tibble(read.dta("https://uofi.box.com/shared/static/bba3968d7c3397c024ec.dta"))
dd| order | ctryname | year | aclpcode | cowcode | cowcode2 | ccdcodelet | ccdcodenum | aclpyear | cowcode2year | cowcodeyear | chgterr | ychgterr | flagc_cowcode2 | flage_cowcode2 | entryy | exity | cid | wdicode | imf_code | politycode | bankscode | dpicode | uncode | un_region | un_region_name | un_continent | un_continent_name | aclp_region | bornyear | endyear | dupcow | dupwdi | dupun | dupdpi | dupimf | dupbanks | exselec | legselec | closed | dejure | defacto | defacto2 | lparty | incumb | type2 | collect | nheads | nmil | nhead | npost | ndate | eheads | ageeh | emil | royal | headdiff | ehead | epost | edate | tenure08 | comm | ecens08 | edeath | flageh | democracy | assconfid | poppreselec | regime | tt | ttd | tta | flagc | flagdem | flagreg | agedem | agereg | stra |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Afghanistan | 1946 | 142 | 700 | 700 | AFG | 1 | 1421946 | 7001946 | 7001946 | 0 | 0 | 1 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 11.08.33 | 0 | 14 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 11.08.33 | 20 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 1 | 1 | 1 | 18 | 18 | 0 |
| 2 | Afghanistan | 1947 | 142 | 700 | 700 | AFG | 1 | 1421947 | 7001947 | 7001947 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 15 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 19 | 0 | ||
| 3 | Afghanistan | 1948 | 142 | 700 | 700 | AFG | 1 | 1421948 | 7001948 | 7001948 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 16 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 20 | 20 | 0 | ||
| 4 | Afghanistan | 1949 | 142 | 700 | 700 | AFG | 1 | 1421949 | 7001949 | 7001949 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 17 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 21 | 21 | 0 | ||
| 5 | Afghanistan | 1950 | 142 | 700 | 700 | AFG | 1 | 1421950 | 7001950 | 7001950 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 18 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 22 | 22 | 0 | ||
| 6 | Afghanistan | 1951 | 142 | 700 | 700 | AFG | 1 | 1421951 | 7001951 | 7001951 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 19 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 23 | 23 | 0 |
Exercici 11. Condicions de democràcia: Examina el llibre de codis de la DD dataset i respon a les següents preguntes (per conèixer com utilitzar un llibre de codis consulteu aquí):
- Descriu cada un dels indicadors/condicions que conformen l’índex DD. Què representen? Utiltiza els termes de condició suficient i necessària per explicar, una per una, les condicions que s’han de donar perquè l’índex sigui 1.
- Escull-ne un país en un any concret i fes una explicació exhaustiva de quina era la situació del país agafant com a referència les condicions que es descriuen a la base de dades. Observa la llista de països amb
names(dd$ctryname)i introdueix el nom del país que seleccionis en aquest codi:
dd %>%
filter(ctryname == "Nom del país") %>% #introdueix nom del país
select(ctryname, year, exselec:type2, democracy) %>%
View()En el següent codi hem simulat com funcionaria la lògica d’agregació de les variables que es mostra en el llibre de codis. Amb la funció if_else() indiquem que retorni un valor 1 només quan totes les condicions especificades es compleixin i valor 0 quan no es compleixin. Amb aquest procediment hem creat la variable dem2 dins del nou objecte dd_index.
dd_index <- dd %>%
mutate(dem2 = if_else(exselec <= 2 &
legselec == 2 &
closed == 2 &
dejure == 2 &
defacto == 2 &
defacto2 == 2 &
lparty == 2 &
type2 == 0 &
incumb == 0,
1, 0)) %>% #retorna 1 si es compleixen, 0 si no es compleixen
select(ctryname, year, dem2, un_continent_name)Practica 13. Una nova mesura de democràcia: Canvia les condicions del codi per veure quantes democràcies hi hauria si:
- Es considerés que pot existir una democràcia sense alternança en el poder (criteri
type2). - L’elecció directa és un criteri necessari per la democràcia (criteri
exselec <=1).
Un cop guardis els canvis a dd_index, podràs saber el nombre de democràcies en un any determinat de la següent manera:
dd_index %>%
filter(year == 2000) %>% #introdueix l'any
summarize(n = sum(dem2))Exercici 12. Una nova mesura de democràcia: Un grup d’acadèmics minimalistes ortodoxos amb molta influència a les institucions internacionals, l’Escola de Barcelona, creu que s’han d’endurir els criteris per considerar que un país és una democràcia. Per això han decidit contractar els teus serveis. T’han demanat que elaboris una proposta que suggereixi algunes modificacions en els criteris de democràcia de la DD dataset. Hauràs de fer canvis al codi que t’hem proporcionat i guardar-los a l’objecte dd_index. L’informe hauria de constar dels següents apartats:
- Comença amb una discussió conceptual: Per què creus que és necessari canviar els criteris de democràcia? T’hauràs d’ajudar de l’article acadèmic per respondre aquesta pregunta (Cheibub, Gandhi, and Vreeland 2010), que trobaràs a la web de Cheibub.
- Fes una breu explicació de la DD dataset. Què mesura? Com ho mesura?
- Quins valors perduts hi ha? Et pots ajudar d’aquest codi per respondre-ho.
filter(dd_index, is.na(dem2))- Fes una proposta per canviar la manera com s’agreguen els indicadors per conformar l’índex de democràcia. Pots modificar un o varis indicadors o fins i tot en pots eliminar. Procura que la teva proposta deixi un mínim de 30% de democràcies a la mostra. Amb el següent codi veuràs el nou nombre de democràcies i el percentatge sobre el total.
summarize(dd_index, perc_dem = 100 * mean(dem2 == 1, na.rm = TRUE),
sum_dem = sum(dem2 == 1, na.rm = TRUE))- Visualitza els resultats per continents i fes una descripció de l’evolució.
dd_index %>%
filter(un_continent_name != "") %>%
group_by(un_continent_name, year) %>%
summarize(perc_dem = mean(dem2 == 1, na.rm = TRUE)) %>%
ggplot(aes(x = year, y = perc_dem, col = un_continent_name)) +
geom_line()Pandemic Backsliding Index
Un exemple de variant no-dicotòmica d’un índex lògic el podem trobar en el Pandemic Backsliding Index (PBI), que va crear el grup de Varieties of Democracy (V-Dem) per mesurar el retrocés democràtic dels governs durant les primeres setmanes de pandèmia del Covid-19 (Edgell et al. 2020). En la primera versió de l’índex, V-Dem va establir varis indicadors que registraven la intensitat de les mesures d’emergència preses per cada país en diversos àmbits. A partir d’aquests indicadors, i seguint la lògica de suficiència, va classificar els països en tres categories segons el seu risc de retrocés democràtic: risc baix, risc mitjà i risc alt. D’aquest estudi en va sortir un dels primers informes del risc que suposava la pandèmia per la democràcia.
A continuació descarregarem el PBI v1.1 i el convertirem en l’objecte pbi. Hem demanat un glimpse(pbi) per veure totes les variables en un llistat vertical. Fixeu-vos que sembla que les dades es van recollir a meitats d’abril de 2020 i que els indicadors que mesuren les mesures d’emergència comencen amb la lletra q. Quan acaben amb _source sembla indicar la font d’on han tret la informació. Finalment, cap al final del marc de dades, hi ha altres variables com el continent o el nivell de democràcia del país segons l’índex V-Dem.
download.file("https://www.jordimas.cat/files/pandemV1_1.csv",
"pandemV1_1.csv")
pbi <- read_csv("pandemV1_1.csv")## Rows: 179
## Columns: 103
## $ time <chr> "2020/04/11 1:18:23 AM EST", "2020/04/11 9:59:37…
## $ country_name <chr> "Afghanistan", "Albania", "Algeria", "Angola", "…
## $ country_text_id <chr> "AFG", "ALB", "DZA", "AGO", "ARG", "ARM", "AUS",…
## $ pan_index_black <chr> "green", "orange", "orange", NA, "orange", "gree…
## $ pan_index <chr> "green", "orange", "orange", NA, "orange", "gree…
## $ q1 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, NA, 0, 1, 1, 0…
## $ q1_source <chr> "https://www.aa.com.tr/en/asia-pacific/afghan-po…
## $ q2 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, NA, 0, 1, 1, 0…
## $ q3 <chr> "18-Apr-20", "25-Apr-20", "19-Apr-20", NA, "12-A…
## $ q2_3_source <chr> "https://www.devdiscourse.com/article/headlines/…
## $ q4 <dbl> 1, 1, 0, NA, 0, 1, 1, 0, 0, 1, 0, NA, 0, 0, 0, 0…
## $ q4_source <chr> "https://www.devdiscourse.com/article/headlines/…
## $ q5 <dbl> 2, 0, 2, NA, 0, 0, 0, 2, 1, 0, 1, NA, 0, 0, 3, 0…
## $ q5_source <chr> "https://en.wikipedia.org/wiki/2020_coronavirus_…
## $ q6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q6_source <chr> NA, "https://shqiptarja.com/lajm/qeveria-shpall-…
## $ q7 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_0 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 0, 1, 1, NA, 1, 1, 1, 1…
## $ q7_1 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_4 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_7 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_source <chr> NA, "https://shqiptarja.com/lajm/qeveria-shpall-…
## $ q8 <dbl> 3, 4, 4, NA, 4, 3, 3, 4, 3, 3, 3, NA, 0, 4, 3, 2…
## $ q8_source <chr> "I chose 3 here because the strict lockdown only…
## $ q9 <dbl> 3, 4, 3, NA, 4, 1, 1, 3, 2, 3, 3, NA, 0, 3, 3, 2…
## $ q9_source <chr> "Again, I chose 3 here because the strict lockdo…
## $ q10 <dbl> 0, 0, 1, NA, 0, 0, 0, 0, 0, 1, 2, NA, 0, 0, 0, 0…
## $ q10_source <chr> "Yet, there have been many problems relating to …
## $ q11 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q11_0 <dbl> 1, 1, 0, NA, 1, 1, 1, 1, 1, 1, 0, NA, 1, 1, 1, 1…
## $ q11_1 <dbl> 0, 0, 1, NA, 0, 1, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q11_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q11_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q11_4 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q11_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q11_source <chr> NA, "https://www.albaniandailynews.com/index.php…
## $ q12 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, NA, 1, 1, 1, 1…
## $ q12_0 <dbl> 1, 1, 1, NA, 0, 0, 1, 1, 1, 1, 0, NA, 1, 1, 1, 1…
## $ q12_1 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_4 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q12_6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q12_7 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_8 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_9 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_10 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q12_11 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_12 <dbl> 0, 0, 0, NA, 1, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_13 <dbl> 0, 0, 0, NA, 0, 1, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_source <chr> "https://www.idea.int/news-media/multimedia-repo…
## $ q13 <dbl> 1, 1, 3, NA, 0, 0, 0, 0, 0, 0, 2, NA, 0, 2, 0, 0…
## $ q13_source <chr> "https://www.devdiscourse.com/article/headlines/…
## $ q14 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, NA, 1, 1, 1, 1…
## $ q14_0 <dbl> 1, 0, 1, NA, 0, 1, 0, 1, 1, 0, 0, NA, 1, 1, 1, 1…
## $ q14_1 <dbl> 0, 0, 0, NA, 0, 1, 0, 0, 0, 0, 0, NA, 0, 0, 1, 0…
## $ q14_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q14_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 1, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q14_4 <dbl> 0, 1, 0, NA, 1, 0, 0, 0, 0, 1, 1, NA, 0, 0, 0, 0…
## $ q14_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q14_6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q14_7 <dbl> 0, 0, 0, NA, 0, 0, 1, 0, 1, 0, 0, NA, 0, 0, 0, 0…
## $ q14_8 <dbl> 0, 1, 0, NA, 1, 0, 0, 0, 1, 0, 0, NA, 0, 0, 0, 0…
## $ q14_9 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q14_10 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 1, 0, NA, 0, 0, 0, 0…
## $ q14_source <chr> "It is hard to find reliable sources on this - t…
## $ q15 <dbl> 0, 2, 0, NA, 1, 0, 1, 0, 0, 4, 3, NA, 0, 0, 0, 0…
## $ q15_source <chr> "Same here, but I got the impression that the li…
## $ q16 <dbl> 1, 1, 1, NA, 2, 1, 1, 1, 2, 1, 3, NA, 1, 1, 1, 1…
## $ q16_source <chr> "https://www.aa.com.tr/en/asia-pacific/afghan-po…
## $ q17 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_0 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_1 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_4 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_source <chr> NA, "https://a2news.com/2020/03/20/koronavirusi-…
## $ q18 <dbl> 0, 0, 0, NA, 0, 1, 0, 0, 1, 1, NA, NA, 1, 0, 1, …
## $ q18_detail <chr> NA, NA, NA, NA, NA, "1) already abolished (sort …
## $ q18_source <chr> NA, NA, NA, NA, NA, "https://hetq.am/en/article/…
## $ green <dbl> 1, 0, 0, NA, 0, 1, 1, 1, 0, 0, 0, NA, 1, 1, 1, 1…
## $ orange <dbl> 0, 1, 1, NA, 1, 0, 0, 0, 1, 1, 1, NA, 0, 0, 0, 0…
## $ red <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 1, 1, NA, 0, 0, 0, 0…
## $ pan_type <chr> "green", "orange", "orange", NA, "orange", "gree…
## $ v2x_polyarchy <dbl> 0.347, 0.481, 0.300, 0.386, 0.812, 0.805, 0.838,…
## $ v2x_libdem <dbl> 0.212, 0.431, 0.119, 0.230, 0.631, 0.641, 0.789,…
## $ v2x_libdem_codelow <dbl> 0.190, 0.382, 0.097, 0.201, 0.587, 0.590, 0.742,…
## $ v2x_libdem_codehigh <dbl> 0.242, 0.482, 0.141, 0.256, 0.687, 0.702, 0.854,…
## $ v2xcl_rol <dbl> 0.305, 0.937, 0.529, 0.552, 0.842, 0.895, 0.969,…
## $ v2mecenefm_osp <dbl> 1.850, 1.724, 0.931, 2.180, 3.136, 3.096, 3.650,…
## $ v2mecenefm_ord <chr> "Direct but limited", "Direct but limited", "Ind…
## $ v2x_regime <dbl> 1, 1, 1, 1, 2, 1, 3, 3, 1, 0, 1, 3, 1, 3, 1, 3, …
## $ v2x_regime_amb <chr> "Electoral Autocracy", "Electoral Autocracy Uppe…
## $ v2x_freexp <dbl> 0.517, 0.694, 0.506, 0.692, 0.936, 0.846, 0.914,…
## $ e_regionpol_6C <chr> "Asia and Pacific", "E. Europe and C. Asia", "ME…
## $ v2x_libdem_t10_sub_bi <dbl> 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, -1, 0, 0, 0, -1, 0…La metodologia utilitzada per elaborar l’índex la podeu trobar en el llibre de codis (pàgines 3-6). És un tant complicada, però és important observar com s’agreguen els indicadors per conformar l’índex PBI.
Exercici 3. La democràcia en risc: Observa atentament el llibre de codis PBI i respon a les següents preguntes:
- Identifica el nombre d’observacions, nombre de variables i la unitat d’anàlisi del marc de dades.
- Explica el significat de la variable
v2x_regime_ambi descriu les seves categories ambtable(pbi$v2x_regime_amb). - Quines són, en general, les mesures d’emergència principals que té en compte l’índex?
- Descriu de forma més concreta com s’han operacionalitzat les mesures d’emergència: escull UNA mesura de la Q2 a la Q4 i UNA mesura de la Q8 a la Q17. Explica en quins casos són condició suficient per a cada categoria de l’índex final.
- Els indicadors Q6 i Q7 fan referència a la ICCPR. Investiga quines normes internacionals han tingut en compte per desenvolupar aqueste mesures. Pots ajudar-te del Working Paper Autocratization by Decree: States of Emergency and Democratic Decline per respondre a la pregunta.
Hem de tenir en compte que aquests índexs lògics segueixen un procés de normalització, agregació i ponderació teòric.
Escales
Les escales han estat una eina metodològica emprada especialment per la sociologia per mesurar empíricament conceptes socials mitjançant qüestionaris a la població, com el grau de religiositat, de prejudici o l’alienació. El sociòleg Earl R. Babbie té un recull dels varis tipus d’escales existents en el seu llibre The Practice of Social Research (Babbie 2013: 215-223). En aquest apartat ens detindrem a estudiar l’escala de Likert. Encara que no és una tècnica especialment utilitzada en temes de política internacional, ens és molt útil per veure un altra manera de crear una mesura composta a través de la lògica de conjunts.
Les escales es construeixen a partir de la premissa que existeix una certa jerarquia d’intensitat en els indicadors: no tots són igual d’importants a l’hora de configurar l’escala. Per tant, hi ha una certa ordinalitat entre ells. Suposem que volem mesurar el grau de confiança vers els altres que té una població i passem un qüestionari amb diverses preguntes: creu que es pot confiar amb la família? I amb els veïns? I amb les persones que no coneix? I amb els immigrants? Respondre que no es pot confiar en les persones que coneixes no indica la mateixa intensitat de la variable que volem mesurar que respondre que no es pot confiar en la família. Per això, les escales es distingeixen de la resta de mesures compostes que estableixen una certa ordinalitat entre els indicadors.
Seguint amb l’exemple anterior, utilitzarem la darrera enquesta de World Values Survey (WVS) (Inglehart et al. 2020) per il·lustrar-ho. La WVS va ser fundada el 1981 per Ronald F. Inglehart, un il·lustre de la ciència política2, i organitza cada cinc anys enquestes sobre els valors de la població mundial. La intenció del projecte és cobrir tota la població mundial i en les successives onades han anat ampliant el nombre de països. En la darrera onada 2017-2021 han cobert fins 80 països. Podeu fer-vos una idea dels països coberts a cada onada a l’eina online de la seva web.
La WVS requereix registrar-se per poder descarregar la base de dades. El primer que hem de fer és anar a la web de darrera onada de l’enquesta, la WVS7, i descarregar l’arxiu “WVS Cross-National Wave 7 R v1 4.zip” i descomprimir-lo. Un cop tinguem l’arxiu descomprimit en el nostre directori de treball, hi aplicarem el següent codi:
load("WVS_Cross-National_Wave_7_R_v1_4.rdata")
wvs7 <- `WVS_Cross-National_Wave_7_R_v1_4`
rm(`WVS_Cross-National_Wave_7_R_v1_4`)Exercici 14. Explorar la WVS: Utilitza el codi glimpse(wvs7) i la documentació que trobaràs a la pàgina per respondre a les següents preguntes:
- Quina cobertura ha tingut l’enquesta en les darreres onades? Què pot explica que en alguns països s’hagi fet l’enquesta i en altres no?
- Indica si, en aquesta present onada, encara s’han de publicar els resultats d’algunes enquestes. A quins països?
- Quina és la unitat d’anàlisi de la WVS7? Quantes observacions i quantes variables té el marc de dades
wvs7? - En quins àmbits estan agrupades les preguntes del qüestionari? Selecciona un àmbit i fes una ullada a la distribució dels valors de quatre de les seves variables amb:
hist(wvs7$nom_variable)- Observa les preguntes que es fan al qüestionari. Quines preguntes es podrien agrupar per mesurar, en diferent escala, un concepte semblant?
A l’apartat de l’enquesta Social Capital, Trust and Organizational Membership, trobem un bon exemple de variables que ens poden servir per crear una escala de Likert. El terme ‘grau de confiança vers els altres’ es podria mesurar a partir de les següents variables. Si l’enquestat respon en l’ítem en qüestió que hi confia completament, la resposta es codifica com a 1. Si hi confia força té valor 2, si no hi confia gaire valor 3 i si no hi confia gens valor 4:
- I ’d like to ask you how much you trust people from various groups. Could you tell me for each whether you trust people from this group completely, somewhat, not very much or not at all?
- Q58: Your family
- Q59: Your neighborhood
- Q60: People you know personally
- Q62: People of another religion
- Q63: People of another nationality
- Q61: People you meet for the first time
Podríem pensar que algunes d’aquestes variables mostren una intensitat més alta del terme ‘grau de confiança vers els altres.’ Per exemple, podríem ordenar les variables en escala, de menor a major intensitat, de la següent manera: Q58, Q60, Q59, Q62, Q63, Q61. Com que tenim els resultats, podem veure si hi ha un cert ordre ‘empíric’ en la manera com hem ordenat les variables. A la Figura 3 observem les respostes per a cada pregunta.
wvs7 %>%
select(Q58, Q59, Q60, Q61, Q62, Q63) %>% #selecciona les variables
gather(preg, val) %>%
ggplot(aes(x = val)) +
geom_histogram(binwidth = 1, fill = "#73edff") +
facet_wrap(~ preg) +
theme_light()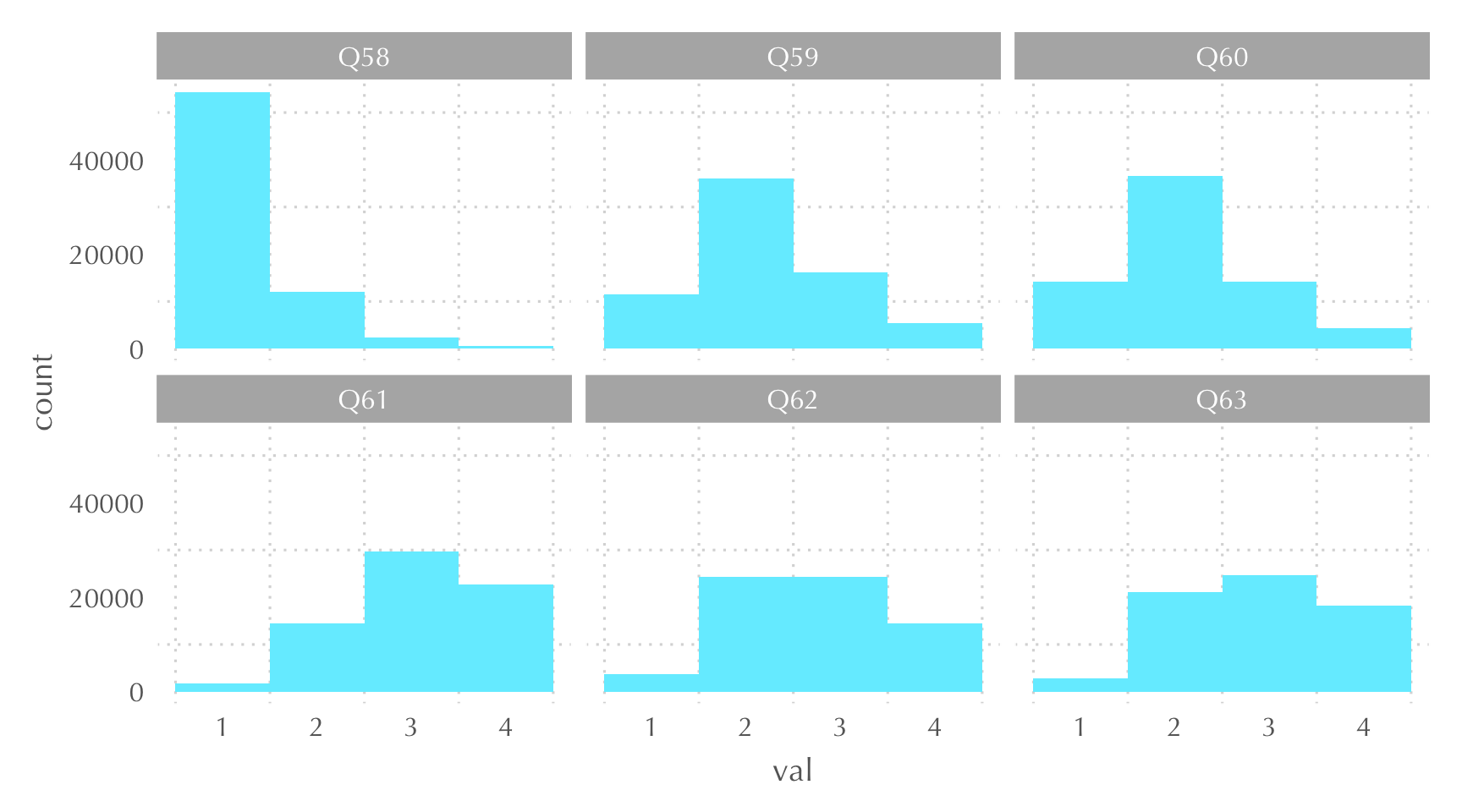
Figure 3: Nivells de confiança segons diverses categories
Sembla que sí que hi ha una certa ordinalitat en com hem pensat l’escala: a la pregunta 58 els valors estan més propers a 1, mentre que a la pregunta Q61 els valors són més propers a 4. Ara ja només ens queda construir l’escala. Per a això, hem creat el marc de dades wvs7_conf, que conté la nova variable conf, operacionalitzada de la següent manera:
- Si l’enquestat respon que desconfia “bastant” o “molt” amb la família (Q58), deduïm que és una persona que té un grau de confiança molt baix vers els altres, de manera que li assignarem un valor 0.
- Si l’enquestat respon que desconfia “bastant” o “molt” amb les persones que coneix personalment (Q60), deduïm que és una persona que té un grau de confiança baix vers els altres, de manera que li assignarem un valor 1.
- Si l’enquestat respon que desconfia “bastant” o “molt” amb els veïns (Q59), deduïm que és una persona que té un grau de confiança força baix vers els altres, de manera que li assignarem un valor 2.
- Si l’enquestat respon que desconfia “bastant” o “molt” amb les persones d’una altra religió (Q62), deduïm que és una persona que té un grau de confiança mitjà vers els altres, de manera que li assignarem un valor 3.
- Si l’enquestat respon que desconfia “bastant” o “molt” amb els persones d’una altra nacionalitat (Q63), deduïm que és una persona que té un grau de confiança relativament alt vers els altres, de manera que li assignarem un valor 4.
- Si l’enquestat respon que desconfia “bastant” o “molt” amb les persones que coneix per primer cop (Q61), deduïm que és una persona que té un grau de confiança alt vers els altres, de manera que li assignarem un valor 5.
- Si l’enquestat respon confia “bastant” o “molt” amb les persones que coneix per primer cop (Q61), deduïm que és una persona que té un grau de confiança molt alt vers els altres, de manera que li assignarem un valor 6.
Tota aquesta lògica es troba resumida en el següent codi:
wvs7_conf <- wvs7 %>%
select(Q58:Q63) %>%
mutate(conf = case_when(Q58 > 2 ~ 0, #family
Q60 > 2 ~ 1, #know personally
Q59 > 2 ~ 2, #neigbourhood
Q62 > 2 ~ 3, #religion
Q63 > 2 ~ 4, #nationality
Q61 > 2 ~ 5, #not know
TRUE ~ 6)) #othersFinalment, només ens queda visualitzar el resultat de la nova variable conf, on mesurem el nivell de confiança vers els altres. Podem veure els resultats a la Figura 4.
wvs7_conf %>%
mutate(conf = as.character(conf)) %>%
ggplot(aes(x = conf)) +
geom_bar(fill = "#73edff") +
theme_light()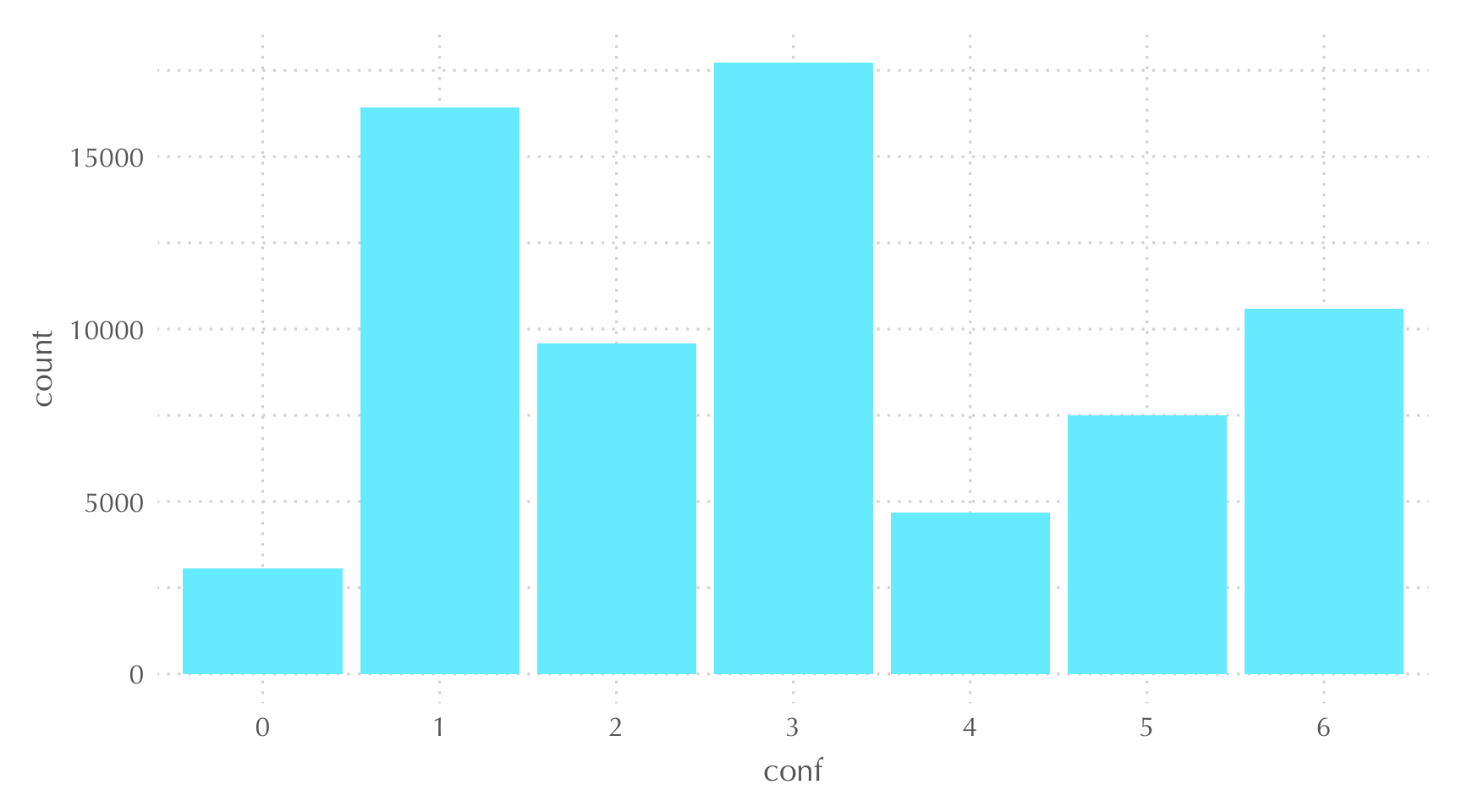
Figure 4: Escala de confiança vers els altres (WVS7)
Exercici 15. Construcció d’una escala: Crea una escala d’un concepte a través d’algun grup d’indicadors que trobaràs a la WVS7. Ajuda’t dels codis exposats anteriorment i fes els següents passos:
- Consulta el qüestionari i el llibre de codis de les variables i selecciona un grup de variables (mínim tres) que et poden servir per crear l’escala d’un determinat concepte.
- Estableix una jerarquia entre les variables seleccionades i fes-ne una justificació teòrica. Pots ajudar-te també d’una justificació empírica a partir de construir una graella d’histogrames semblants als de la Figura 3.
- Construeix l’escala a partir de l’ordre jeràrquic que hagis establert. Si és necessari, modifica el codi per afegeix o eliminar els valors de l’escala que creguis necessaris.
- Genera un diagrama de barres que mostri el recompte de valors per a cada categoria de l’escala. Fes una descripció dels resultats.
En aquest apartat hem vist només un tipus d’escala, l’escala de Likert. És important precisar que no totes les altres escales utilitzen la mateixa lògica de conjunts. No obstant, sí que es caracteritzen per assumir una certa ordinalitat entre variables.
Referències
La secció de les variables ordinals us pot ajudar a familiaritzar-vos amb les condicions lògiques: igual que, més gran que, més petit que, etc.↩︎
El seu estudi més conegut va ser la identificació d’una generació amb valors postmaterialistes que sorgia a partir dels anys 1980 i es distingia de les generacions anteriors, de valors més materialistes↩︎