La corba de Kuznets
Branko Milanovic i Simon Kuznets són dos dels acadèmics més coneguts en els estudis de la desigualtat. A cada un d’ells se’l coneix per identificar una determinada trajectòria de la desigualtat en un període de temps determinat:
- L’elefant de Milanovic: La diferencia en percentatge de guany entre la distribució per nivell d’ingressos l’any 2008 i l’any 1988 fa forma d’elefant.
- La corba de Kuznets: A mesura que la riquesa d’un país creix amb el procés d’industrialització, en una primera fase les desigualtats creixen i en una segona fase decreixen, de manera que la relació entre creixement econòmic i desigualtats té forma de U invertida.
En aquesta pràctica observarem la trajectòria que descriu la corba de Kuznets. Aquest economista nordamericà va teoritzar el 1955 que a mesura que la riquesa d’un país creix amb el procés d’industrialització, en una primera fase les desigualtats creixen i en una segona fase decreixen, de manera que la relació entre creixement econòmic i desigualtats té forma de U invertida.1. En primer lloc, carregarem els paquets que necessitem.
#recordeu que els paquets han d'estar prèviament instal·lats
library(readxl)
library(haven)
library(tidyr)
library(dplyr)
library(ggplot2)
library(wbstats)La corba de Kuznets
Simon Kuznets va formular el 1955 la teoria que la relació entre el progrés d’un país i la desigualtat tindria forma de U invertida. En una fase inicial de desenvolupament econòmic, els països són pobres i hi ha poques diferències en nivell d’ingressos entre la seva població. La industrialització porta a una segona fase de desenvolupament, en què només una petita minoria pot treure’n profit dels seus beneficis, de manera que les desigualtats creixerien en aquest segon període. Amb el progrés i el pas del temps s’arribaria a una tercera fase, en què cada vegada més persones podrien participar dels beneficis de la industrialització, de manera que les desigualtats es veurien reduïdes.
Aquestes són les conclusions que va treure Kuznets a partir d’observar la relació entre ingrés i desigualtats a Estats Units durant el període 1913-1948 en la seva obra Shares of Upper Income Groups in Income and Savings (Kuznets 1953). El seu estudi ha estat replicat desenes de vegades amb resultats dispars. En aquest exercici intentarem fer una nova rèplica de la corba de Kuznets.
Exercici 1: En primer lloc, indaga sobre l’obra de Kuznets a partir dels textos La Desigualdad entre Personas (Milanovic 2011) i El Capital del Siglo XXI (Piketty 2014) i respon a les següents preguntes:
- Per què l’obra de Kuznets és revolucionària des d’un punt de vista empíric?
- Kuznets utilitza una font d’informació principal per elaborar el seu estudi. De quin tipus de font es tracta? Aquest tipus de font és incompleta per saber les desigualtats a la població. Quina altra font va necessitar? Per què?
- En la relació de causalitat que estudia Kuznets, quina és la variable dependent i quina és la variable independent?
- Descriu breument què és l’índex de Gini.
Per replicar l’estudi de Kuznets, necessitarem estudiar la relació entre dues variables numèriques:
- Desigualtat: Mesurada amb l’índex de Gini.
- Desenvolupament: Mesurada amb el PIB per càpita.
Dades de desigualtat
Una de les sèries temporals més llargues que conté informació sobre l’índex de Gini la trobem al All the Ginis Dataset del Banc Mundial.
Exercici 2: Accedeix a la pàgina web All the Ginis Dataset i busca a la pestanya Data & Resources el document que conté la descripció de la base de dades:
- De quantes bases de dades diferents s’han obtingut els índexs de Gini per crear All the Ginis Dataset?
- Quantes observacions Gini recull en total la base de dades?
- Quin és el nom de la variable que engloba tots els ginis de les altres bases de dades?
- Algunes variables que ens trobarem a la base de dades porten els prefixos
Dhh,DincoDgross. Aquestes variables poden prendre el valor 1 o el valor 0. Explica el significat d’aquestes variables a partir de la Digressió 1 de Desigualdad Global (Milanovic 2016: 26-31). Per què és rellevant aquesta distinció? - Suposa que tenim dos hipotètics països que tenen el mateix Gini però que un té el valor 1 a la variable
Dinci l’altre el valor 0. Tindrien la mateixa desigualtat? Raona la teva resposta. - Quina és la dècada on tenim més observacions?
- De quina regió (segons la nomenclatura utilitzada) tenim més observacions en relació al nombre de països?
Ara que ja tenim una orientació general sobre les dades que hem de tractar, ja podem descarregar la base de dades i netejar-la de variables que no ens interessin i de dades perdudes. En el següent codi hem realitzat les següents operacions: hem descarregat la base de dades, hem seleccionat algunes de les variables i hem eliminat tots els NA. El resultat és el marc de dades ginis, on podem observar les seves primeres files a la següent Taula 1.
download.file("https://development-data-hub-s3-public.s3.amazonaws.com/ddhfiles/94536/allginis_2013.xls",
"allginis.xls")
ginis <- read_xls("allginis.xls", sheet = 2) %>%
select(country:year, Giniall) %>% #seleccionem algunes variables
filter(!is.na(Giniall)) #eliminem dades perdudes| country | contcod | region | year | Giniall |
|---|---|---|---|---|
| Albania | ALB | Eastern Europe | 1997 | 28.6 |
| Albania | ALB | Eastern Europe | 2002 | 29.4 |
| Albania | ALB | Eastern Europe | 2004 | 31.1 |
| Albania | ALB | Eastern Europe | 2005 | 31.7 |
| Albania | ALB | Eastern Europe | 2008 | 30.4 |
| Algeria | DZA | Africa | 1988 | 38.8 |
| Algeria | DZA | Africa | 1995 | 34.6 |
| Angola | AGO | Africa | 1995 | 40.2 |
| Angola | AGO | Africa | 2000 | 58.1 |
| Argentina | ARG | Latin America | 1974 | 34.5 |
Una ullada ràpida al marc de dades amb head(ginis, 10) o glimpse(ginis) ens permet comprovar que tenim molt pocs casos d’alguns països. Ja només al principi de la llista veiem que tenim dades d’Albània en només cinc anys, per dos d’Algèria i dos d’Angola. Ja d’entrada, sabem que serà difícil observar l’evolució de la desigualtat en alguns països si tenim tant pocs punts en el temps.
Si utilitzem range(ginis$year) veiem que tenim dades des de 1950 fins a 2012, encara que no tenim la mateixa quantitat d’observacions de tots els països. Podem investigar de quants anys tenim registre a cada país amb count(). Aquesta funció ens fa un recompte de casos per cada variable categòrica que indiquem. Sempre que posem al final d’un codi %>% View() podem veure els resultats en una finestra nova amb format de full de càlcul. A la Taula 2 observem els resultats.
ginis %>%
count(country, sort = TRUE) %>% #demanem un recompte i que ens ordeni els resultats
head(30) %>% View() #demanem les primeres 30 observacions i visualitzar la taula en una finestra a part| country | n |
|---|---|
| United States | 62 |
| United Kingdom | 50 |
| Bulgaria | 42 |
| India | 42 |
| Brazil | 36 |
| Taiwan, China | 34 |
| Italy | 33 |
| Poland | 33 |
| China | 32 |
| Japan | 31 |
| Costa Rica | 30 |
| Mexico | 30 |
| Argentina | 28 |
| Venezuela, Rep | 28 |
| Denmark | 27 |
| Iran,IslamicRep. | 27 |
| Netherlands | 27 |
| Colombia | 26 |
| Sweden | 26 |
| Canada | 25 |
| Germany | 25 |
| Hungary | 25 |
| Chile | 24 |
| Honduras | 23 |
| Norway | 23 |
| Peru | 23 |
| Pakistan | 22 |
| El Salvador | 21 |
| Panama | 21 |
| Spain | 21 |
Exercici 3: Com podeu comprovar, tenim més dades d’alguns països que no pas d’altres. Per algun motiu, doncs, des de 1950 fins a 2012 moltes dades estan perdudes.
- Sabries dir quines característiques tenen en comú, en general, els països dels que tenim més dades? I els països dels que tenim menys dades? Posa alguns exemples d’acord amb els resultats que has obtingut en la Taula 2.
- Amb el següent codi hem demanat l’any més antic (
min()) i l’any recent (max()) de què tenim dades a cada país, així com el recompte de casos (n()). Selecciona un país que tingui menys de 25 casos i, a partir de les dades generades pel codi, intenta explicar des d’un punt de vista històric per quin motiu aquest país concret té més/menys dades en relació als altres països.
ginis %>%
group_by(country) %>%
summarize(min = min(year),
max = max(year),
n = n()) %>%
arrange(desc(n))Dades de desenvolupament
Tal com va fer Kuznets en el seu estudi, utilitzarem el PIB per càpita com a mesura de desenvolupament econòmic. Encara que el PIB per càpita ha tingut i està tenint cada vegada més crítiques com a mesura de desenvolupament (Stiglitz, Sen, and Fitoussi 2010), també és cert que continua sent una mesura senzilla, fiable, disponible i prou acceptada per acadèmics i decisors públics.
Per obtenir les dades del PIB per càpita, utilitzarem el paquet wbstats que ens proporciona dades del Banc Mundial. Amb la funció wb_search() busquem indicadors que continguin les paraules gdp, capita i ppp. Veiem que obtenim cinc resultats.
wb_search("gdp.*capita.*ppp")## # A tibble: 4 x 3
## indicator_id indicator indicator_desc
## <chr> <chr> <chr>
## 1 6.0.GDPpc_cons… GDP per capita, PPP (co… GDP per capita based on purchasing p…
## 2 NY.GDP.PCAP.PP… GDP per capita, PPP (cu… This indicator provides per capita v…
## 3 NY.GDP.PCAP.PP… GDP per capita, PPP (co… GDP per capita based on purchasing p…
## 4 NY.GDP.PCAP.PP… GDP per capita, PPP ann… Annual percentage growth rate of GDP…Ens interessen les dades de PIB per càpita a preus constants, però com podeu observar en el resultat tenim tres variables que sembla que ens ofereixin exactament el mateix. Com que no estem segurs de quina variable escollir, descarregarem tots cinc resultats i els compararem entre ells per tenir més clara la nostra elecció. En el següent codi fem els següents procediments:
- Guardem els codis dels indicadors a l’objecte
gdpcap. Teclegeu el nom del nou objecte per comprovar que efectivament conté els codis dels indicadors. - Amb la funció
wb()descarreguem el marc de dades que anomenaremincome. A dins de la funció hi especifiquem el nom del vector on hem guardat els indicadors. - A continuació separem (
pivot_wider()) els indicadors per tal que cada variable estigui en una columna diferent i demanem un sumari.
gdpcap <- wb_search("gdp.*capita.*ppp") %>% pull(indicator_id)
income <- wb_data(indicator = gdpcap, return_wide = F) %>%
mutate(date = as.numeric(date)) %>%
as_tibble()
income %>%
pivot_wider(names_from = indicator_id, values_from = value) %>%
summary()## indicator iso2c iso3c country
## Length:29606 Length:29606 Length:29606 Length:29606
## Class :character Class :character Class :character Class :character
## Mode :character Mode :character Mode :character Mode :character
##
##
##
##
## date unit obs_status footnote
## Min. :1960 Length:29606 Length:29606 Length:29606
## 1st Qu.:1975 Class :character Class :character Class :character
## Median :1990 Mode :character Mode :character Mode :character
## Mean :1990
## 3rd Qu.:2005
## Max. :2020
##
## last_updated 6.0.GDPpc_constant NY.GDP.PCAP.PP.CD NY.GDP.PCAP.PP.KD
## Min. :2013-02-22 Min. : 3475 Min. : 285.6 Min. : 436.7
## 1st Qu.:2021-07-21 1st Qu.: 6451 1st Qu.: 2723.4 1st Qu.: 3496.6
## Median :2021-07-21 Median : 9254 Median : 7707.2 Median : 10201.3
## Mean :2020-09-09 Mean : 9909 Mean : 14950.4 Mean : 17877.8
## 3rd Qu.:2021-07-21 3rd Qu.:12900 3rd Qu.: 20266.7 3rd Qu.: 25759.3
## Max. :2021-07-21 Max. :21980 Max. :154095.2 Max. :162915.8
## NA's :29366 NA's :24004 NA's :23917
## NY.GDP.PCAP.PP.KD.ZG
## Min. :-50.290
## 1st Qu.: -1.453
## Median : 1.504
## Mean : 1.405
## 3rd Qu.: 4.037
## Max. : 92.586
## NA's :27433Exercici 4: Investigueu el marc de dades income amb les funcions head() i glimpse(), així com els estadístics descriptius dels indicadors per separat que hem obtingut amb summary().
- Quin és l’indicador que ens ha eliminat? Quina informació contenia?
- Si us hi fixeu, en el marc de dades original
incomeno tenim les variables del PIB per càpita separades, cada una en una columna diferent. Totes ens han vingut agrupades en una columna que hem hagut de separar per tal de tenir cada variable en una columna diferent. Quin és el nom la variable que contenia el codi dels indicadors que hem hagut de separar? - Tenim dues variables amb codis de països. Quines són?
- Per què és preferible utilitzar dades a preus constants enlloc de preus corrents a l’hora d’estudiar el desenvolupament econòmic?
- Quantes dades perdudes (
NA) té cada variable? - Tenint en compte tota aquesta informació, amb quina variable et quedaries de les quatre que tenim disponibles? Indica el codi de l’indicador i justifica la resposta.
- Amb el que has après en aquest exercici, utilitza el següent codi per remenar la base de dades del Banc Mundial amb
wb_search()i buscar un indicador que trobis interessant. Descriu el marc de dades resultant amb les funcionshead(),glimpse()isummary().
wb_search("?????????") #escull els termes a cercar i identifica el codi de l'indicador que t'interessi
# limita la cerca tant com necessitis amb .* entre paraules: "paraula1.*paraula2.*paraula3"
prova <- wb_data(indicator = "????????") %>% #introdueix el codi de l'indicador
as_tibble()
head(prova)
glimpse(prova)
summary(prova)La corba
Fins ara, en aquesta activitat ens hem dedicat a recollir les dades que necessitàvem per crear la corba de Kuznets. En el primer apartat hem obtingut les dades de desigualtat i en el segon apartat hem recollit dades de desenvolupament. Amb això ja podem crear una corba de Kuznets:
- a nivell mundial, que ens expliqui quina relació han mantingut desenvolupament i desigualtat amb totes les dades que tenim disponibles.
- en un país, que ens expliqui la relació entre desenvolupament i desigualtat en un cas concret.
Per això haurem d’unir els dos marcs de dades creats anteriorment en el nou marc de dades incgini, que veiem a la Taula 3.
incgini <- income %>%
filter(indicator_id == "NY.GDP.PCAP.PP.KD") %>%
transmute(iso3c, year = date, gdpcap = value) %>%
inner_join(ginis, by = c("iso3c" = "contcod", "year"))| iso3c | year | gdpcap | country | region | Giniall |
|---|---|---|---|---|---|
| ALB | 2008 | 9912.577 | Albania | Eastern Europe | 30.4 |
| ALB | 2005 | 8040.879 | Albania | Eastern Europe | 31.7 |
| ALB | 2004 | 7580.629 | Albania | Eastern Europe | 31.1 |
| ALB | 2002 | 6754.536 | Albania | Eastern Europe | 29.4 |
| ALB | 1997 | 4400.578 | Albania | Eastern Europe | 28.6 |
| DZA | 1995 | 7935.179 | Algeria | Africa | 34.6 |
| DZA | 1988 | NA | Algeria | Africa | 38.8 |
| AGO | 2000 | 4727.966 | Angola | Africa | 58.1 |
| AGO | 1995 | 4139.641 | Angola | Africa | 40.2 |
| ARG | 2012 | 24118.868 | Argentina | Latin America | 42.6 |
Exercici 5: Respon a les següents preguntes utilitzant les funcions que s’indiquen segons si l’objecte a explorar en cada cas és el marc de dades incgini o bé una variable concreta del marc de dades (incgini$nom_variable):
- Quantes observacions tenim en aquest nou marc de dades?
glimpse()odim() - Quantes observacions tenim a cada regió?
table() - Quants països diferents tenim?
n_distinct() - Quin és l’any màxim i mínim?
range() - Quin és el PIB per càpita màxim i mínim?
range() - Quina és la observació amb major PIB per càpita? I amb menor? Hauràs d’aplicar
min()imax()a la funció següent:
incgini[which(incgini$gdpcap == ???(incgini$gdpcap)),]En l’exercici anterior ens hem adonat que el marc de dades incgini té poques observacions en relació als marcs de dades d’orígen. Això es deu, principalment, perquè en alguns casos teníem informació del desenvolupament del país però no de la seva desigualtat i en altres casos teníem informació de la desigualtat el país però no del seu desenvolupament. Això ens ha reduït dràsticament les observacions quan hem agrupat les dades.
No obstant, podem intentar crear la corba de Kuznets amb les dades disponibles amb un diagrama de dispersió que trobem a la Figura 1.
- Ubicarem
gdpcapa l’eix de les x. Ginialla l’eix de les y.- A més, aprofitarem la columna
regionper assenyalar la regió en el color dels punts. - La corba la crearem mitjançant
geom_smooth(). - Aplicarem l’escala logarítmica a l’eix de les x per representar millor els valors de la distribució (té una asimetria negativa) i per representar millor la diferència en els efectes que té una unitat addicional en termes de PIB per càpita en els valors baixos i els valors alts de la distribució.
incgini %>%
ggplot(aes(x = gdpcap, y = Giniall)) + #eixos x i y
geom_point(aes(col = region), alpha = .5) + #els punts
geom_smooth(se = FALSE) + #la corba
scale_x_log10() + #escala logarítmica
theme_light() +
theme(legend.position = "bottom",
legend.title = element_blank())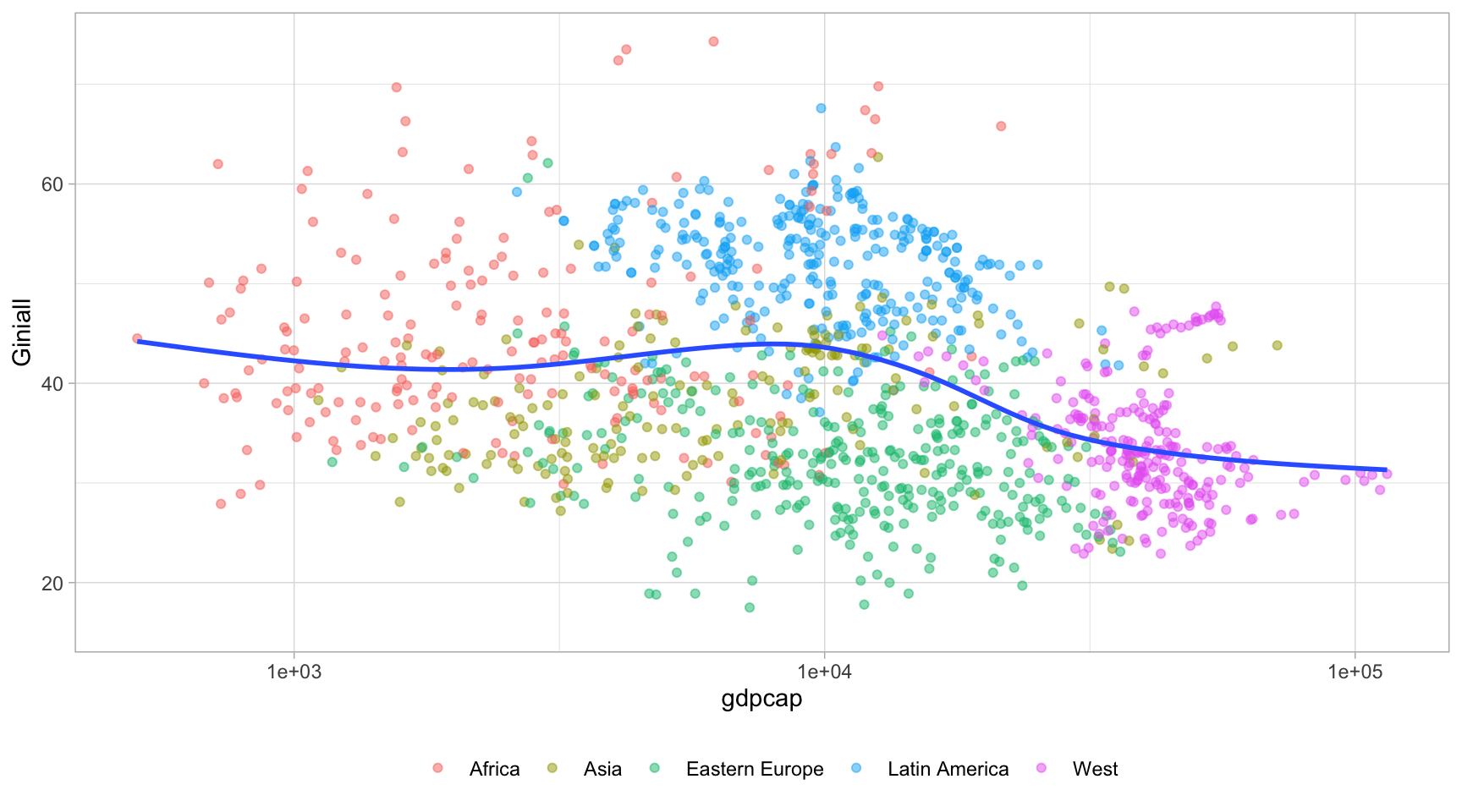
Figure 1: Relació entre desenvolupament i desigualtat mundial (1990-2012)
La corba de Kuznets es distingeix molt tímidament en el gràfic. Sembla que les desigualtats arriben al seu pic als 10.000 dòlars per càpita i a partir de llavors es redueixen conforme el desenvolupament augmenta.
Exercici 6: Observa la Figura 1 i respon a les següents preguntes?
- Tenint en compte els criteris de causalitat, per què diries que hem ubicat
gdpcapa l’eix de les x iGinialla l’eix de les y? - Interpreta l’escala logarítmica de l’eix de les x. Què vol dir 1e+03, 1e+04 i 1e+05? Intenta trobar-hi la lògica associada i explica-la.
- Sembla que hi ha un patró molt clar de les desigualtats per regió geogràfica. Explica, per cada regió, on estan ubicades la majoria de les observacions segons els dos eixos del gràfic?
- Afegeix la següent línia de codi entre la primera i la segona línia del codi que hem utilitzat per crear el gràfic. Escull una regió i reprodueix el gràfic de nou. Comenta el gràfic. S’observa la corba de Kuznets en la regió escollida?
filter(region = "???????") %>%- Com milloraries la validesa de la relació? Pensa en algun indicador més vàlid que el PIB per càpita (bé sigui un indicador dins de la família del PIB o un altre tipus d’indicador).
Cas d’estudi
Per fer l’exercici final utilitzarem una altra font d’informació molt emprada en estudis de desenvolupament econòmic: les Penn World Tables v9.1 (PWT) (Feenstra, Inklaar, and Timmer 2015), que conté una sèrie temporal més llarga que la que hem utilitzat fins ara del Banc Mundial. Això ens permetrà tenir dades anteriors a 1990 en alguns països.
En el següent codi descarreguem l’arxiu de la web de PWT i unim les dades amb les del marc de dades ginis per crear el marc de dades pwtgini. Apliqueu-hi el codi que hem fet servir a l’Exercici 3 per veure l’any mínim, l’any màxim i el nombre d’observacions per a cada país. Trobareu el resultat a la Taula 4.
download.file("https://www.rug.nl/ggdc/docs/pwt91.dta",
"pwt91.dta")
pwt <- read_dta("pwt91.dta") %>%
mutate(gdpcap = rgdpo / pop) %>% #dividim PIB per població per obtenir el PIB per càpita
select(countrycode, year, gdpcap) %>%
filter(!is.na(gdpcap))
pwtgini <- pwt %>%
inner_join(ginis, by = c("countrycode" = "contcod", "year"))| country | min | max | n |
|---|---|---|---|
| United States | 1950 | 2011 | 62 |
| United Kingdom | 1961 | 2010 | 50 |
| India | 1951 | 2009 | 42 |
| Bulgaria | 1970 | 2008 | 37 |
| Brazil | 1960 | 2011 | 36 |
| Taiwan, China | 1964 | 2008 | 34 |
| Italy | 1967 | 2010 | 33 |
| Poland | 1976 | 2009 | 33 |
| China | 1953 | 2007 | 32 |
| Japan | 1962 | 2008 | 31 |
| Costa Rica | 1961 | 2010 | 30 |
| Mexico | 1950 | 2010 | 30 |
| Argentina | 1974 | 2012 | 28 |
| Venezuela, Rep | 1962 | 2011 | 28 |
| Denmark | 1963 | 2008 | 27 |
| Iran,IslamicRep. | 1969 | 2008 | 27 |
| Netherlands | 1962 | 2008 | 27 |
| Colombia | 1964 | 2011 | 26 |
| Sweden | 1963 | 2008 | 26 |
| Canada | 1965 | 2008 | 25 |
| Germany | 1950 | 2008 | 25 |
| Chile | 1968 | 2011 | 24 |
| Honduras | 1968 | 2011 | 23 |
| Hungary | 1972 | 2008 | 23 |
| Norway | 1962 | 2008 | 23 |
| Peru | 1961 | 2011 | 23 |
| Pakistan | 1963 | 2008 | 22 |
| El Salvador | 1965 | 2010 | 21 |
| Panama | 1969 | 2012 | 21 |
| Spain | 1965 | 2010 | 21 |
El país de què disposem més observacions és els Estats Units. En la Figura 2 hem filtrat les dades pel país en qüestió i hem demanat un diagrama de línies (geom_path()) que ens mostra el recorregut que ha seguit, any rera any, la relació entre PIB per càpita i l’índex de Gini. Segons les dades que podem aportar observem que les desigualtats als Estats Units no s’han reduït conforme ha anat avançant el desenvolupament econòmic del país, sinó que han augmentat. Aquestes conclusions disten molt de les dades observades per Kuznets en el període 1913-1948, que van originar la teoria coneguda com la corba de Kuznets.
pwtgini %>%
filter(country == "United States") %>%
ggplot(aes(x = gdpcap, y = Giniall)) +
geom_path(alpha = 0.2, size = 2, lineend = "round", aes(col = year), show.legend = FALSE) +
geom_text(aes(label = year), size = 3, position = position_jitter(width=0.5,height=0.5)) +
labs(title = "Evolució de l'índex de Gini als Estats Units segons PIB per càpita (1950-2011)",
x = "PIB per capita", y = "Índex de Gini") +
theme_bw()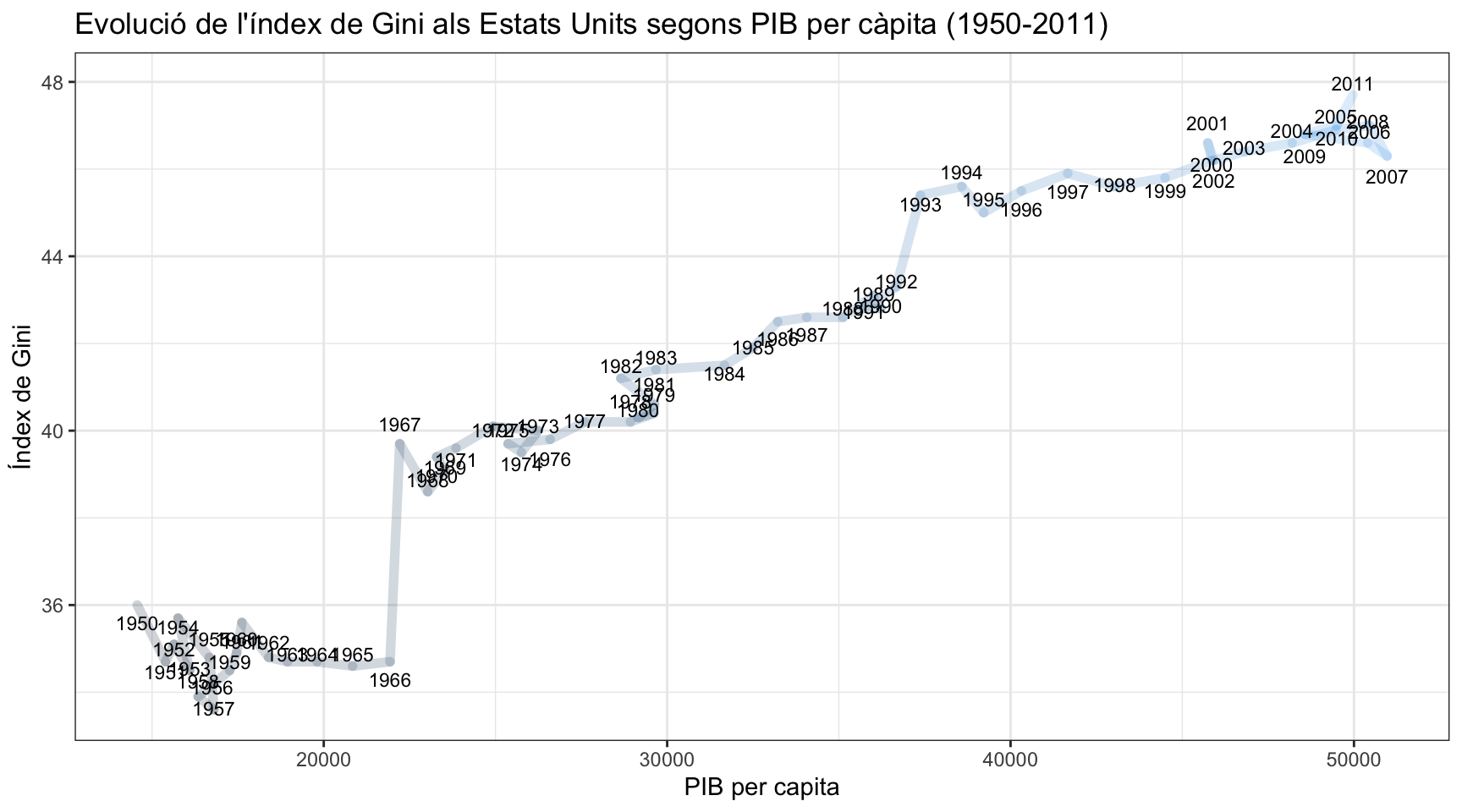
Figure 2: Exercici final: els Estats Units
EXERCICI FINAL: A partir del codi que hem utilitzat per crear la Figura 2, elabora un gràfic amb un altre país que tingui un mínim de 20 observacions.
- Canvia la transparència (
alphapot variar entre 0 i 1) i el gruix (sizeha de ser superior a 0) de la línia. - Canvia la mida del text (
sizeha de ser superior a 0). - Canvia el títol del gràfic.
- Comenta el gràfic: de quins anys tenim dades? quina trajectòria es dibuixa? hi ha canvis sobtats? quedaria validada la teoria de Kuznets en el cas del país que has escollit?
Referències
Aquesta activitat està elaborada amb propòsits estrictament docents. Les operacions que es realitzen no pretenen tenir cap validesa des d’un punt de vista acadèmic↩︎