4. Otras medidas compuestas
Los contenidos de esta obra forman parte de un encargo de autoría de la Universitat Oberta de Catalunya (Mas 2020) y están sujetos a la licencia de Creative Commons CC BY-SA 3.0.

Los índices compuestos siguen los procesos de normalización, ponderación y agregación descritos en el apartado anterior. Más allá de esta estructura, existen otros tipos de medidas compuestas que siguen una lógica diferente en su proceso de construcción. No hay consenso académico en la forma de definir y caracterizar estas medidas. Por ejemplo, Earl R. Babbie distingue entre índices y escalas, aunque las diferencias entre los dos procedimientos de construcción han ido difuminándose con el paso del tiempo (Babbie 2013: 198-199). En este apartado nos centraremos en explicar dos tipos de medidas compuestas que se distinguen de los índices porque están construidas con la lógica de conjuntos (set theory). Esta lógica tiene la particularidad de que los diferentes indicadores no se agrupan mediante fórmulas aritméticas o geométricas, sino que se agrupan y ordenan mediante condiciones de suficiencia y necesidad, muy utilizadas en estudios cualitativos y comparados (Goertz and Mahoney 2012; Rihoux and Ragin 2009). El razonamiento es el siguiente:
Necesidad: la condición es necesaria para indicar la presencia de un determinado concepto. En otras palabras, el concepto no está presente si la condición no está presente.
Suficiencia: la condición es suficiente para indicar la presencia de un determinado concepto. En otras palabras, cuando la condición está presente, el concepto siempre está presente.
Si traducimos lo que acabamos de explicar con algunos ejemplos:
- Tener alas es una condición necesaria para ser un pájaro. Pero ¿es una condición suficiente? No, los aviones tienen alas y no son pájaros.
- Estar en Escocia es condición suficiente para estar en el Reino Unido. Pero ¿es necesaria? No, podemos estar en el Reino Unido desde otros muchos lugares: desde Gales, Manchester o desde la playa de Brighton.
- No presentarse a un examen es condición suficiente para suspenderlo. Pero ¿es necesaria? No, también podemos suspender el examen si nos presentamos, pero no contestamos correctamente las preguntas.
- Los astrónomos creen que la presencia de agua es una condición necesaria para la vida en otros planetas, pero ¿es esto una condición suficiente para la vida? No, también se cree que serían necesarios otros requisitos, como la luz solar o una temperatura estable.
- Democracia, populismo, guerra, diplomacia, revolución.
- Genocidio, terrorismo, organización internacional.
Los criterios de suficiencia y necesidad se ilustran normalmente en una matriz 2x2 como las de la Figura 1. En cada matriz vemos cómo se relaciona la presencia (1) o ausencia (0) del indicador X con la presencia o ausencia del fenómeno Y para establecer una condición necesaria o suficiente.

Figure 1: Condición suficiente y condición necesaria | Goertz and Mahoney (2012)
- En la parte izquierda, vemos que X es condición necesaria para Y cuando X es 0. Entonces, sabemos seguro que Y no puede ser 1.
- En la parte derecha, vemos que X es condición suficiente para Y cuando X no es 1. Entonces, sabemos que Y tiene que ser por fuerza 0.
Los dos tipos de medidas compuestas que veremos en este apartado funcionan con la lógica de conjuntos. Al primer tipo, lo llamaremos índices lógicos, que construyen la medida compuesta sin seguir ningún orden específico en sus variables. Es decir, las variables se combinan entre sí sin presuponer ningún tipo de rango entre ellas y conforman el índice final a partir de ciertas condiciones de suficiencia y necesidad. Al segundo tipo, lo llamaremos escalas –y explicaremos exclusivamente la escala de Likert–, que sí asumen un orden específico entre variables, de forma que los indicadores que componen la medida siguen una jerarquía de intensidad.
En este apartado utilizaremos los siguientes paquetes:
library(foreign)
library(dplyr)
library(readr)
library(ggplot2)
library(tidyr)Índices lógicos
Los índices lógicos podrían considerarse, simplemente, índices, con la única diferencia de que siguen un razonamiento fundamentado en los conjuntos lógicos, de forma que los resultados quedan ordenados en categorías discretas ordenables. Uno de los terrenos de la ciencia política donde más se ha usado esta lógica ha sido en los estudios de democracia. Algunos autores defienden que la existencia de democracia en un determinado país viene condicionada por la presencia de unas determinadas condiciones, necesarias y en conjunto suficientes (Przeworski et al. 2000). Este razonamiento ha dado origen a las clasificaciones dicotómicas de democracia, que establecen dos categorías para determinar si un régimen político es una democracia (1) o si no lo es (0).
Democracy-Dictatorship Dataset
Una de las clasificaciones más usadas en los estudios internacionales es la Democracy-Dictatorship (DD) dataset (Cheibub, Gandhi, and Vreeland 2010). Si consultamos su libro de códigos, nos encontraremos con la siguiente Figura 2, que puede leerse como: «tendremos presencia de democracia si la variable exselect es igual o inferior a 2 y la variable legselect es igual a 2 y la variable closed es igual a 2 y la variable dejure es igual a 2 y la variable defacto es igual a 2 y la variable defacto2 es igual a 2 y la variable lparty es igual a 2 y la variable type2 es igual a 0 y la variable incumb es igual a 0»1.

Figure 2: Condiciones de democracia de la DD Dataset
Podemos descargar y consultar la base de datos por medio del código que aparece a continuación, a partir del cual hemos generado el objeto dd que representamos en la siguiente Tabla 1. Podéis ayudaros de los de la sección Democracia binaria para hacer una exploración a fondo del marco de datos.
library(foreign)
library(dplyr)
dd <- as_tibble(read.dta("https://uofi.box.com/shared/static/bba3968d7c3397c024ec.dta"))
dd| order | ctryname | year | aclpcode | cowcode | cowcode2 | ccdcodelet | ccdcodenum | aclpyear | cowcode2year | cowcodeyear | chgterr | ychgterr | flagc_cowcode2 | flage_cowcode2 | entryy | exity | cid | wdicode | imf_code | politycode | bankscode | dpicode | uncode | un_region | un_region_name | un_continent | un_continent_name | aclp_region | bornyear | endyear | dupcow | dupwdi | dupun | dupdpi | dupimf | dupbanks | exselec | legselec | closed | dejure | defacto | defacto2 | lparty | incumb | type2 | collect | nheads | nmil | nhead | npost | ndate | eheads | ageeh | emil | royal | headdiff | ehead | epost | edate | tenure08 | comm | ecens08 | edeath | flageh | democracy | assconfid | poppreselec | regime | tt | ttd | tta | flagc | flagdem | flagreg | agedem | agereg | stra |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Afghanistan | 1946 | 142 | 700 | 700 | AFG | 1 | 1421946 | 7001946 | 7001946 | 0 | 0 | 1 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 11.08.33 | 0 | 14 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 11.08.33 | 20 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 1 | 1 | 1 | 18 | 18 | 0 |
| 2 | Afghanistan | 1947 | 142 | 700 | 700 | AFG | 1 | 1421947 | 7001947 | 7001947 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 15 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 19 | 0 | ||
| 3 | Afghanistan | 1948 | 142 | 700 | 700 | AFG | 1 | 1421948 | 7001948 | 7001948 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 16 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 20 | 20 | 0 | ||
| 4 | Afghanistan | 1949 | 142 | 700 | 700 | AFG | 1 | 1421949 | 7001949 | 7001949 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 17 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 21 | 21 | 0 | ||
| 5 | Afghanistan | 1950 | 142 | 700 | 700 | AFG | 1 | 1421950 | 7001950 | 7001950 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 18 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 22 | 22 | 0 | ||
| 6 | Afghanistan | 1951 | 142 | 700 | 700 | AFG | 1 | 1421951 | 7001951 | 7001951 | 0 | 0 | 0 | 0 | 1946 | 2008 | 700 | AFG | 512 | 700 | 10 | AFG | 4 | 34 | Southern Asia | 142 | Asia | 9 | 1919 | 2008 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Mohammad Zahir Shah | king | 0 | 19 | 0 | 1 | 0 | Mohammad Zahir Shah | king | 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 23 | 23 | 0 |
Ejercicio 11. Condiciones de democracia: examinad el libro de códigos de la DD Dataset y responded a las siguientes preguntas (para aprender cómo utilizar un libro de códigos consultad aquí):
- Describid cada uno de los indicadores o condiciones que conforman el índice DD. ¿Qué representan? Usad los términos de condición suficiente y necesaria para explicar, una por una, las condiciones que tienen que darse para que el índice sea 1.
- Escoged un país en un año concreto y haced una explicación exhaustiva de cuál era la situación del país tomando como referencia las condiciones que se describen en la base de datos. Observad la lista de países con
names(dd$ctryname)e introducid el nombre del país que seleccionéis en este código:
dd %>%
filter(ctryname == "Nombre del país") %>% #introduce el nombre del país
select(ctryname, year, exselec:type2, democracy) %>%
View()En el siguiente código, hemos simulado cómo funcionaría la lógica de agregación de las variables que se muestra en el libro de códigos. Con la función if_else(), indicamos que devuelva un valor 1 solo cuando todas las condiciones especificadas se cumplan, y valor 0 cuando no se cumplan. Con este procedimiento, hemos creado la variable dem2 dentro del nuevo objeto dd_index.
dd_index <- dd %>%
mutate(dem2 = if_else(exselec <= 2 &
legselec == 2 &
closed == 2 &
dejure == 2 &
defacto == 2 &
defacto2 == 2 &
lparty == 2 &
type2 == 0 &
incumb == 0,
1, 0)) %>% #devuelve 1 si se cumplen, 0 si no se cumplen
select(ctryname, year, dem2, un_continent_name)Practica 13. Una nueva medida de democracia: Cambia las condiciones del código anterior para observar cuantas hay si:
- Se considera que puede existir una democracia sin alternanza en el poder (criterio
type2). - La elección directa es un criterio necesario para la democracia (criterio
exselec <=1).
Una vez guardes los cambios en dd_index, podrás saber el número de democracias en un año determinado de la siguente manera:
dd_index %>%
filter(year == 2000) %>% #introduce el año
summarize(n = sum(dem2))Ejercicio 12. Una nueva medida de democracia: un grupo de académicos minimalistas ortodoxos con mucha influencia en las instituciones internacionales, la Escuela de Barcelona, cree que tienen que endurecerse los criterios para considerar que un país es una democracia. Por eso, han decidido contratar vuestros servicios. Os han pedido que elaboréis una propuesta que sugiera algunas modificaciones en los criterios de democracia de la DD Dataset. Tendréis que hacer cambios en el código que os hemos proporcionado y guardarlos en el objeto dd_index. El informe debería constar de los siguientes apartados:
- Empezad con una discusión conceptual: ¿por qué creéis que es necesario cambiar los criterios de democracia? Para responder a esta pregunta, tendréis que ayudaros del artículo académico (Cheibub, Gandhi, and Vreeland 2010), que encontraréis en la web de Cheibub.
- Haced una breve explicación de la DD Dataset. ¿Qué mide? ¿Cómo lo mide?
- ¿Qué valores perdidos hay? Podéis ayudaros de este código para responderlo:
filter(dd_index, is.na(dem2))- Haced una propuesta para cambiar la forma en la que se agregan los indicadores para conformar el índice de democracia. Podéis modificar uno o varios indicadores, o incluso podéis eliminarlos. Procurad que vuestra propuesta deje un mínimo del 30 % de democracias en la muestra. Con el siguiente código, veréis el nuevo número de democracias y el porcentaje sobre el total:
summarize(dd_index, perc_dem = 100 * mean(dem2 == 1, na.rm = TRUE),
sum_dem = sum(dem2 == 1, na.rm = TRUE))- Visualizad los resultados por continentes y haced una descripción de la evolución.
library(ggplot2)
dd_index %>%
filter(un_continent_name != "") %>%
group_by(un_continent_name, year) %>%
summarize(perc_dem = mean(dem2 == 1, na.rm = TRUE)) %>%
ggplot(aes(x = year, y = perc_dem, col = un_continent_name)) +
geom_line()Pandemic Backsliding Index
Un ejemplo de variante no dicotómica de un índice lógico podemos encontrarlo en el Pandemic Backsliding Index (PBI), creado por el grupo Varieties of Democracy (V-Dem) para medir el retroceso democrático de los gobiernos durante las primeras semanas de pandemia de la COVID-19 (Edgell et al. 2020). En la primera versión del índice, V-Dem estableció varios indicadores que registraban la intensidad de las medidas de emergencia tomadas por cada país en varios ámbitos. A partir de estos indicadores, y siguiendo la lógica de suficiencia, clasificó los países en tres categorías según su riesgo de retroceso democrático: riesgo bajo, riesgo medio y riesgo alto. De este estudio salió uno de los primeros informes del riesgo que suponía la pandemia para la democracia.
A continuación, descargaremos el PBI v1.1 y lo convertiremos en el objeto pbi. Hemos pedido un glimpse(pbi) para ver todas las variables en un listado vertical. Fijaos que parece que los datos se recogieron a mediados de abril de 2020 y que los indicadores que miden las medidas de emergencia empiezan con la letra q. Cuando acaban con _source, parece indicar la fuente de donde han sacado la información. Finalmente, hacia el final del marco de datos, hay otras variables, como el continente o el nivel de democracia del país según el índice V-Dem.
library(readr)
library(dplyr)
download.file("https://www.jordimas.cat/files/pandemV1_1.csv",
"pandemV1_1.csv")
pbi <- read_csv("pandemV1_1.csv")## Rows: 179
## Columns: 103
## $ time <chr> "2020/04/11 1:18:23 AM EST", "2020/04/11 9:59:37…
## $ country_name <chr> "Afghanistan", "Albania", "Algeria", "Angola", "…
## $ country_text_id <chr> "AFG", "ALB", "DZA", "AGO", "ARG", "ARM", "AUS",…
## $ pan_index_black <chr> "green", "orange", "orange", NA, "orange", "gree…
## $ pan_index <chr> "green", "orange", "orange", NA, "orange", "gree…
## $ q1 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, NA, 0, 1, 1, 0…
## $ q1_source <chr> "https://www.aa.com.tr/en/asia-pacific/afghan-po…
## $ q2 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, NA, 0, 1, 1, 0…
## $ q3 <chr> "18-Apr-20", "25-Apr-20", "19-Apr-20", NA, "12-A…
## $ q2_3_source <chr> "https://www.devdiscourse.com/article/headlines/…
## $ q4 <dbl> 1, 1, 0, NA, 0, 1, 1, 0, 0, 1, 0, NA, 0, 0, 0, 0…
## $ q4_source <chr> "https://www.devdiscourse.com/article/headlines/…
## $ q5 <dbl> 2, 0, 2, NA, 0, 0, 0, 2, 1, 0, 1, NA, 0, 0, 3, 0…
## $ q5_source <chr> "https://en.wikipedia.org/wiki/2020_coronavirus_…
## $ q6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q6_source <chr> NA, "https://shqiptarja.com/lajm/qeveria-shpall-…
## $ q7 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_0 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 0, 1, 1, NA, 1, 1, 1, 1…
## $ q7_1 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_4 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_7 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q7_source <chr> NA, "https://shqiptarja.com/lajm/qeveria-shpall-…
## $ q8 <dbl> 3, 4, 4, NA, 4, 3, 3, 4, 3, 3, 3, NA, 0, 4, 3, 2…
## $ q8_source <chr> "I chose 3 here because the strict lockdown only…
## $ q9 <dbl> 3, 4, 3, NA, 4, 1, 1, 3, 2, 3, 3, NA, 0, 3, 3, 2…
## $ q9_source <chr> "Again, I chose 3 here because the strict lockdo…
## $ q10 <dbl> 0, 0, 1, NA, 0, 0, 0, 0, 0, 1, 2, NA, 0, 0, 0, 0…
## $ q10_source <chr> "Yet, there have been many problems relating to …
## $ q11 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q11_0 <dbl> 1, 1, 0, NA, 1, 1, 1, 1, 1, 1, 0, NA, 1, 1, 1, 1…
## $ q11_1 <dbl> 0, 0, 1, NA, 0, 1, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q11_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q11_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q11_4 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q11_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q11_source <chr> NA, "https://www.albaniandailynews.com/index.php…
## $ q12 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, NA, 1, 1, 1, 1…
## $ q12_0 <dbl> 1, 1, 1, NA, 0, 0, 1, 1, 1, 1, 0, NA, 1, 1, 1, 1…
## $ q12_1 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_4 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q12_6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q12_7 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_8 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_9 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_10 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q12_11 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_12 <dbl> 0, 0, 0, NA, 1, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_13 <dbl> 0, 0, 0, NA, 0, 1, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q12_source <chr> "https://www.idea.int/news-media/multimedia-repo…
## $ q13 <dbl> 1, 1, 3, NA, 0, 0, 0, 0, 0, 0, 2, NA, 0, 2, 0, 0…
## $ q13_source <chr> "https://www.devdiscourse.com/article/headlines/…
## $ q14 <dbl> 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, NA, 1, 1, 1, 1…
## $ q14_0 <dbl> 1, 0, 1, NA, 0, 1, 0, 1, 1, 0, 0, NA, 1, 1, 1, 1…
## $ q14_1 <dbl> 0, 0, 0, NA, 0, 1, 0, 0, 0, 0, 0, NA, 0, 0, 1, 0…
## $ q14_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q14_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 1, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q14_4 <dbl> 0, 1, 0, NA, 1, 0, 0, 0, 0, 1, 1, NA, 0, 0, 0, 0…
## $ q14_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 1, NA, 0, 0, 0, 0…
## $ q14_6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q14_7 <dbl> 0, 0, 0, NA, 0, 0, 1, 0, 1, 0, 0, NA, 0, 0, 0, 0…
## $ q14_8 <dbl> 0, 1, 0, NA, 1, 0, 0, 0, 1, 0, 0, NA, 0, 0, 0, 0…
## $ q14_9 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q14_10 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 1, 0, NA, 0, 0, 0, 0…
## $ q14_source <chr> "It is hard to find reliable sources on this - t…
## $ q15 <dbl> 0, 2, 0, NA, 1, 0, 1, 0, 0, 4, 3, NA, 0, 0, 0, 0…
## $ q15_source <chr> "Same here, but I got the impression that the li…
## $ q16 <dbl> 1, 1, 1, NA, 2, 1, 1, 1, 2, 1, 3, NA, 1, 1, 1, 1…
## $ q16_source <chr> "https://www.aa.com.tr/en/asia-pacific/afghan-po…
## $ q17 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_0 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_1 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_2 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_3 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_4 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_5 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_6 <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 0, 0, NA, 0, 0, 0, 0…
## $ q17_source <chr> NA, "https://a2news.com/2020/03/20/koronavirusi-…
## $ q18 <dbl> 0, 0, 0, NA, 0, 1, 0, 0, 1, 1, NA, NA, 1, 0, 1, …
## $ q18_detail <chr> NA, NA, NA, NA, NA, "1) already abolished (sort …
## $ q18_source <chr> NA, NA, NA, NA, NA, "https://hetq.am/en/article/…
## $ green <dbl> 1, 0, 0, NA, 0, 1, 1, 1, 0, 0, 0, NA, 1, 1, 1, 1…
## $ orange <dbl> 0, 1, 1, NA, 1, 0, 0, 0, 1, 1, 1, NA, 0, 0, 0, 0…
## $ red <dbl> 0, 0, 0, NA, 0, 0, 0, 0, 0, 1, 1, NA, 0, 0, 0, 0…
## $ pan_type <chr> "green", "orange", "orange", NA, "orange", "gree…
## $ v2x_polyarchy <dbl> 0.347, 0.481, 0.300, 0.386, 0.812, 0.805, 0.838,…
## $ v2x_libdem <dbl> 0.212, 0.431, 0.119, 0.230, 0.631, 0.641, 0.789,…
## $ v2x_libdem_codelow <dbl> 0.190, 0.382, 0.097, 0.201, 0.587, 0.590, 0.742,…
## $ v2x_libdem_codehigh <dbl> 0.242, 0.482, 0.141, 0.256, 0.687, 0.702, 0.854,…
## $ v2xcl_rol <dbl> 0.305, 0.937, 0.529, 0.552, 0.842, 0.895, 0.969,…
## $ v2mecenefm_osp <dbl> 1.850, 1.724, 0.931, 2.180, 3.136, 3.096, 3.650,…
## $ v2mecenefm_ord <chr> "Direct but limited", "Direct but limited", "Ind…
## $ v2x_regime <dbl> 1, 1, 1, 1, 2, 1, 3, 3, 1, 0, 1, 3, 1, 3, 1, 3, …
## $ v2x_regime_amb <chr> "Electoral Autocracy", "Electoral Autocracy Uppe…
## $ v2x_freexp <dbl> 0.517, 0.694, 0.506, 0.692, 0.936, 0.846, 0.914,…
## $ e_regionpol_6C <chr> "Asia and Pacific", "E. Europe and C. Asia", "ME…
## $ v2x_libdem_t10_sub_bi <dbl> 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, -1, 0, 0, 0, -1, 0…La metodología utilizada para elaborar el índice podéis encontrarla en el libro de códigos (págs. 3-6). Es un tanto complicada, pero es importante observar cómo se agregan los indicadores para conformar el índice PBI.
Ejercicio 13. La democracia en riesgo: observad atentamente el libro de códigos PBI y responded a las siguientes preguntas:
- Identificad el número de observaciones, el número de variables y la unidad de análisis del marco de datos.
- Explicad el significado de la variable
v2x_regime_cony describid sus categorías contable(pbi$v2x_regime_con). - ¿Cuáles son, en general, las medidas de emergencia principales que tiene en cuenta el índice?
- Describid de forma más concreta cómo se han operacionalizado las medidas de emergencia: escoged una medida de la Q2 a la Q4 y una medida de la Q8 a la Q17. Explicad en qué casos son condición suficiente para cada categoría del índice final.
- Los indicadores Q6 y Q7 hacen referencia a la ICCPR. Investigad qué normas internacionales han tenido en cuenta para desarrollar estas medidas. Podéis ayudaros del documento de trabajo Autocratization by Decree: States of Emergency and Democratic Decline para responder a la pregunta.
Debemos tener en cuenta que estos índices lógicos siguen un proceso de normalización, ponderación y agregación teórico.
Escalas
Las escalas han sido una herramienta metodológica usada especialmente por la sociología para medir empíricamente conceptos sociales mediante cuestionarios a la población, como el grado de religiosidad, los prejuicios o la alienación. El sociólogo Earl R. Babbie tiene una compilación de los diversos tipos de escalas existentes en su libro The Practice of Social Research (Babbie 2013: 215-223). En este apartado, estudiaremos la escala de Likert. Aunque no es una técnica especialmente utilizada en temas de política internacional, nos es muy útil para ver otra forma de crear una medida compuesta con la lógica de conjuntos.
Las escalas se construyen a partir de la premisa de que existe una cierta jerarquía de intensidad en los indicadores: no todos son igual de importantes a la hora de configurar la escala. Por lo tanto, hay una cierta ordinalidad entre ellos. Supongamos que queremos medir el grado de confianza hacia los demás que tiene una población y pasamos un cuestionario con varias preguntas: ¿cree que puede confiarse en la familia? ¿Y en los vecinos? ¿Y en las personas que no conoce? ¿Y en los inmigrantes? Responder que no puede confiarse en las personas que conoces no indica la misma intensidad de la variable que queremos medir que responder que no puede confiarse en la familia. Por eso, las escalas se distinguen del resto de medidas compuestas que establecen una cierta ordinalidad entre los indicadores.
Siguiendo con el ejemplo anterior, utilizaremos la última encuesta del World Values Survey (WVS) (Inglehart et al. 2020) para ilustrarlo. La WVS fue fundada en 1981 por Ronald F. Inglehart, un ilustre de la ciencia política2, y organiza cada cinco años encuestas sobre los valores de la población mundial. La intención del proyecto es cubrir toda la población mundial y en las sucesivas oleadas han ido ampliando el número de países. En la última oleada (2017-2021) han cubierto hasta ochenta países. Podéis haceros una idea de los países cubiertos en cada oleada en la herramienta en línea de su web.
La WVS requiere registrarse para poder descargar la base de datos. Lo primero que tenemos que hacer es ir a la web de la última oleada de la encuesta, la WVS7, descargar el archivo “WVS Cross-National Wave 7 R v1 4.zip” y descomprimirlo. Una vez tengamos el archivo descomprimido en nuestro directorio de trabajo, aplicaremos el siguiente código:
load("WVS_Cross-National_Wave_7_R_v1_4.rdata")
wvs7 <- `WVS_Cross-National_Wave_7_R_v1_4`
rm(`WVS_Cross-National_Wave_7_R_v1_4`)Ejercicio 14. Exploración de la WVS: usad el código glimpse(wvs7) y la documentación que encontrarás en la página para responder a las siguientes preguntas:
- ¿Qué cobertura ha tenido la encuesta en las últimas oleadas? ¿Qué puede explicar que en algunos países se haya hecho la encuesta y en otros no?
- Indicad si, en la presente ola, todavía tienen que publicarse los resultados de algunas encuestas. ¿En qué países?
- ¿Cuál es la unidad de análisis de la WVS7? ¿Cuántas observaciones y cuántas variables tiene el marco de datos
wvs7? - ¿En qué ámbitos están agrupadas las preguntas del cuestionario? Seleccionad un ámbito y echad un vistazo a la distribución de los valores de cuatro de sus variables con:
hist(wvs7$nom_variable)- Observad las preguntas que se hacen en el cuestionario. ¿Qué preguntas podrían agruparse para medir, en diferente escala, un concepto parecido?
En el apartado de la encuesta Social Capital, Trust and Organizational Membership, encontramos un buen ejemplo de variables que pueden servirnos para crear una escala de Likert. El término «grado de confianza hacia los demás» podría medirse a partir de las siguientes variables. Si el encuestado responde en el ítem en cuestión que confía completamente, la respuesta se codifica como 1. Si confía bastante tiene valor 2, si no confía mucho tiene valor 3 y si no confía nada tiene valor 4:
- I ’d like to ask you how much you trust people from various groups. Could you tell me for each whether you trust people from this group completely, somewhat, not very much or not at all?
- Q58: Your family
- Q59: Your neighborhood
- Q60: People you know personally
- Q62: People of another religion
- Q63: People of another nationality
- Q61: People you meet for the first time
Podríamos pensar que algunas de estas variables muestran una intensidad más alta del término «grado de confianza hacia los demás». Por ejemplo, podríamos ordenar las variables en escala, de menor a mayor intensidad, de la siguiente manera: Q58, Q60, Q59, Q62, Q63, Q61. Puesto que tenemos los resultados, podemos ver si hay un cierto orden «empírico» en la forma en la que hemos ordenado las variables. En la Figura 3, observamos las respuestas para cada pregunta.
library(tidyr)
wvs7 %>%
select(Q58, Q59, Q60, Q61, Q62, Q63) %>% #selecciona las variables
gather(preg, val) %>%
ggplot(aes(x = val)) +
geom_histogram(binwidth = 1, fill = "#73edff") +
facet_wrap(~ preg) +
theme_light()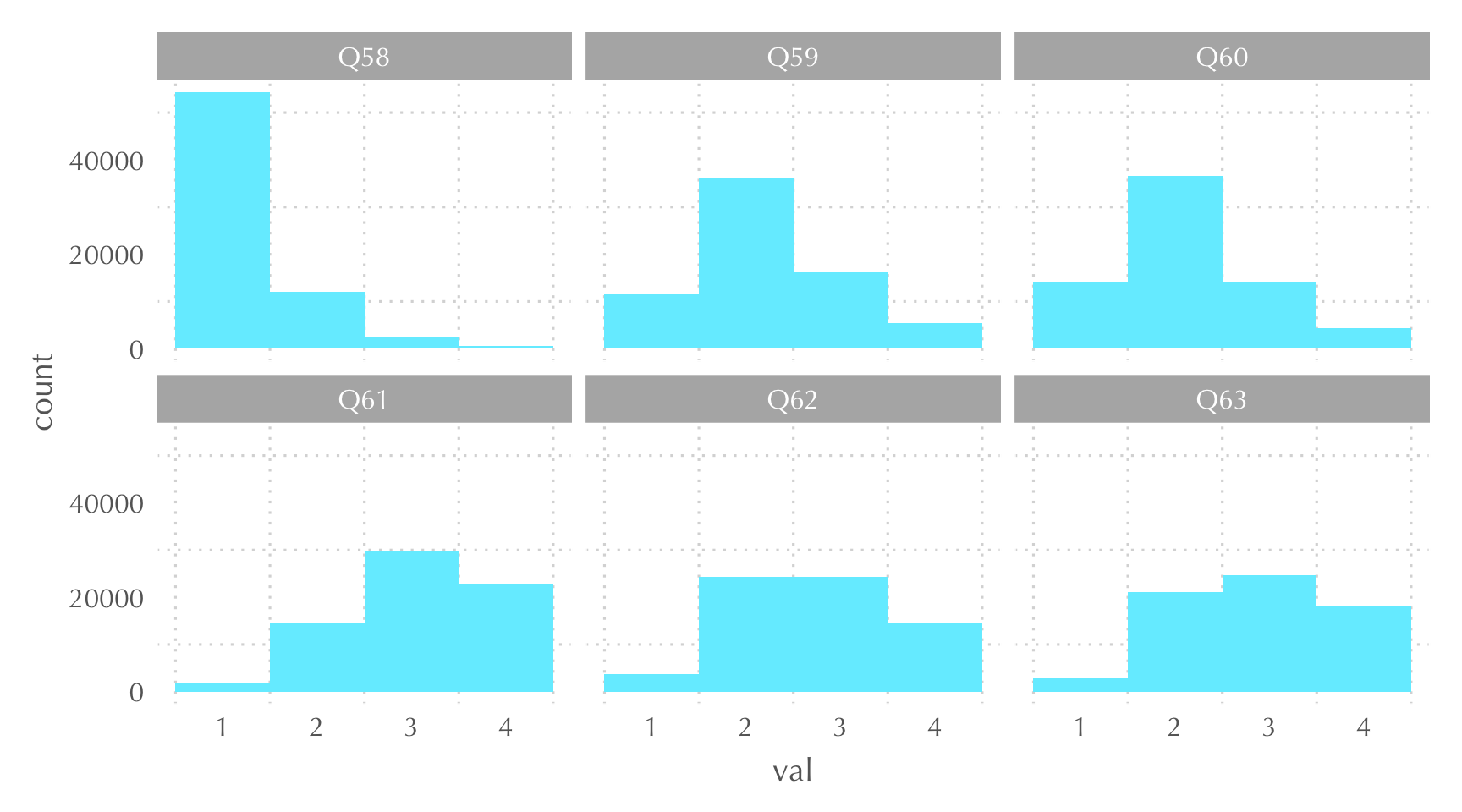
Figure 3: Niveles de confianza según varias categorías
Parece que sí hay una cierta ordinalidad en la forma como hemos pensado la escala: en la pregunta 58 los valores están más próximos a 1, mientras que en la pregunta Q61 los valores son más próximos a 4. Ahora ya solo nos queda construir la escala. Para ello, hemos creado el marco de datos wvs7_conf, que contiene la nueva variable conf, operacionalizada de la siguiente manera:
- Si el encuestado responde que desconfía «bastante» o «mucho» de la familia (Q58), deducimos que es una persona que tiene un grado de confianza muy bajo hacia los otros, de forma que le asignaremos un valor 0.
- Si el encuestado responde que desconfía «bastante» o «mucho» de las personas que conoce personalmente (Q60), deducimos que es una persona que tiene un grado de confianza bajo hacia los demás, de forma que le asignaremos un valor 1.
- Si el encuestado responde que desconfía «bastante» o «mucho» de los vecinos (Q59), deducimos que es una persona que tiene un grado de confianza bastante bajo hacia los demás, de forma que le asignaremos un valor 2.
- Si el encuestado responde que desconfía «bastante» o «mucho» de las personas de otra religión (Q62), deducimos que es una persona que tiene un grado de confianza medio hacia los demás, de forma que le asignaremos un valor 3.
- Si el encuestado responde que desconfía «bastante» o «mucho» de las personas de otra nacionalidad (Q63), deducimos que es una persona que tiene un grado de confianza relativamente alto hacia los demás, de forma que le asignaremos un valor 4.
- Si el encuestado responde que desconfía «bastante» o «mucho» de las personas que conoce por primera vez (Q61), deducimos que es una persona que tiene un grado de confianza alto hacia los demás, de forma que le asignaremos un valor 5.
- Si el encuestado responde confía «bastante» o «mucho» de las personas que conoce por primera vez (Q61), deducimos que es una persona que tiene un grado de confianza muy alto hacia los demás, de forma que le asignaremos un valor 6.
Toda esta lógica se encuentra resumida en el siguiente código:
wvs7_conf <- wvs7 %>%
select(Q58:Q63) %>%
mutate(conf = case_when(Q58 > 2 ~ 0, #family
Q60 > 2 ~ 1, #know personally
Q59 > 2 ~ 2, #neigbourhood
Q62 > 2 ~ 3, #religion
Q63 > 2 ~ 4, #nationality
Q61 > 2 ~ 5, #not know
TRUE ~ 6)) #othersFinalmente, solo nos queda visualizar el resultado de la nueva variable conf, en la que medimos el nivel de confianza hacia los demás. Podemos ver los resultados en la Figura 4.
wvs7_conf %>%
mutate(conf = as.character(conf)) %>%
ggplot(aes(x = conf)) +
geom_bar(fill = "#73edff") +
theme_light()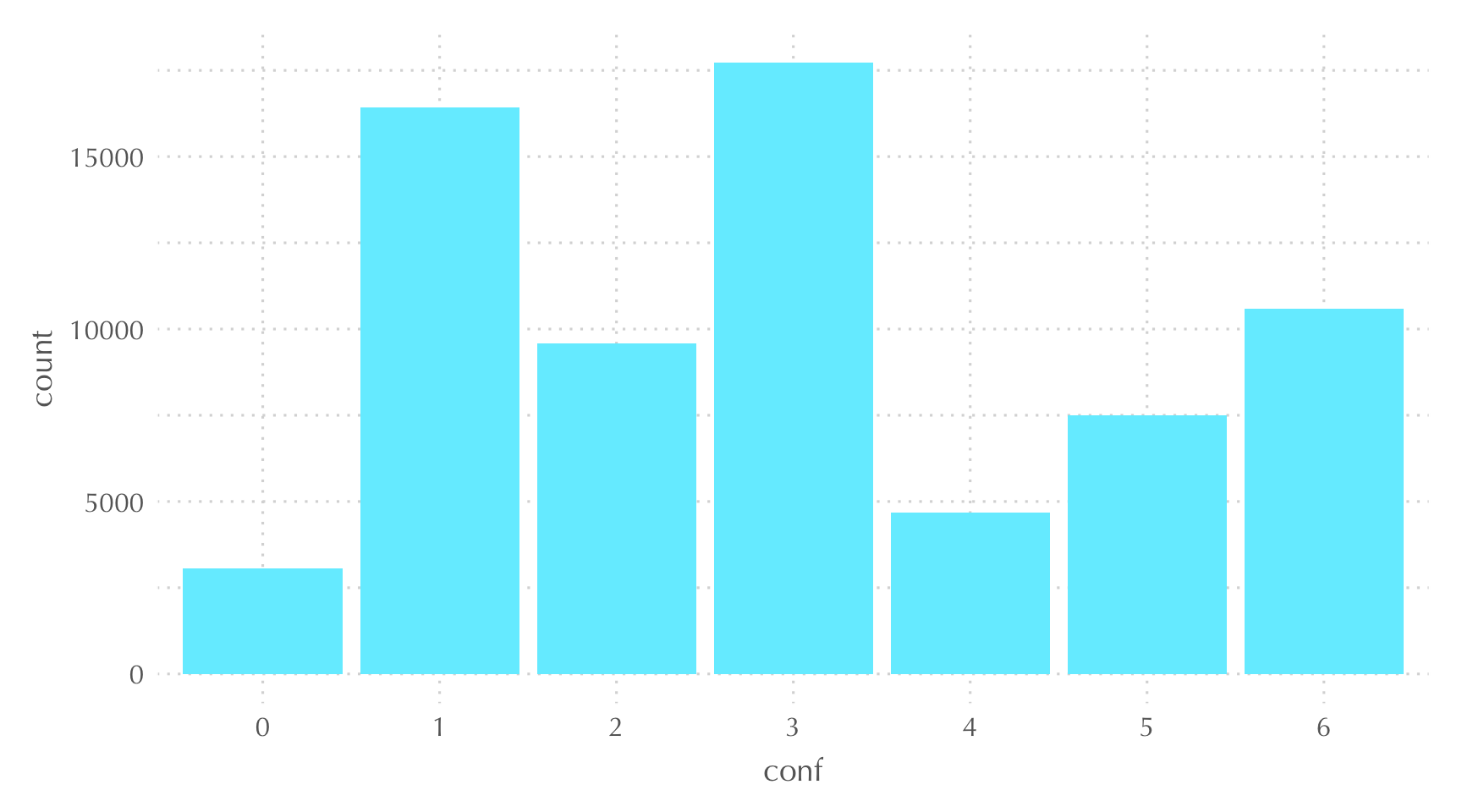
Figure 4: Escala de confianza hacia los demás (WVS7)
Ejercicio 15. Construcción de una escala: cread una escala de un concepto usando algún grupo de indicadores que encontraréis en la WVS7. Ayudaros de los códigos expuestos anteriormente y haced los siguientes pasos:
- Consultad el cuestionario y el libro de códigos de las variables y seleccionad un grupo de variables (mínimo tres) que puedan serviros para crear la escala de un determinado concepto.
- Estableced una jerarquía entre las variables seleccionadas y haced una justificación teórica. Podéis ayudaros, también, de una justificación empírica construyendo una parrilla de histogramas parecidos a los de la Figura 3.
- Construid la escala a partir del orden jerárquico que hayáis establecido. Si es necesario, modificad el código para añadir o eliminar los valores de la escala que creáis necesarios.
- Generad un diagrama de barras que muestre el recuento de valores para cada categoría de la escala. Haced una descripción de los resultados. En este apartado, solo hemos visto un tipo de escala: la escala de Likert. Es importante precisar que no todas las otras escalas utilizan la misma lógica de conjuntos. No obstante, sí se caracterizan por asumir una cierta ordinalidad entre variables.
En este apartado, solo hemos visto un tipo de escala: la escala de Likert. Es importante precisar que no todas las otras escalas utilizan la misma lógica de conjuntos. No obstante, sí se caracterizan por asumir una cierta ordinalidad entre variables.
Referencias
La sección de las variables ordinales os puede ayudar a familiarizaros con las condiciones lógicas: igual que, mayor que, menor que, etc.↩︎
Su estudio más conocido fue la identificación de una generación con valores posmaterialistas que surgía a partir de los años ochenta y se distinguía de las generaciones anteriores, de valores más materialistas.↩︎